Микропроцессоры: Попытки разработки собственной архитектуры
Чт янв 12, 2017 07:08:47
Вариация на тему каким бы мог быть процессор 1975 года, если бы …
Eщё будучи школьником, когда разобрался более-менее в основах работы микропроцессора РАДИО-86РК и открыл, что все сигналы, за исключением выводов частота/ожидание/прерывание/сброс, генерирует сам процессор по мере надобности, начались предприниматься попытки разработки собственного идеального процессора. Конечно, опираясь на опыт работы с ИК80, а позднее - и Z80…
В первую очередь, всегда мною предпринималась попытка разработать идеальную таблицу команд, не требующей существенных усилий для запоминания соответствий машинного кода к мнемонике и самой операции. Что стало моей идеалогией. Так, например, меня возмутило, что в i8086 коду 00 соответствует операция ADD, что сбивает с толку, если память обнулена. В поисках стабильности и защиты от сбоев, коду 00 я навсегда в своих набросках присвоил операцию останова HLT. И это вполне здравое решение.
Когда начал практически разрабатывать эмулятор, пришёл к выводу, что команды условного возврата из подпрограммы - нужные, но излишние в таблице. Система команд x86 изобилует реликтовым хламом, который зря захламляет всё и отжирает драгоценный байт-код: AAA, AAD, AAM, AAS. Команды ENTER/LEAVE используются при входе в подпрограмму и возврате из неё, т.е. не достаточно часто. Честно говоря, было много вариантов с перестановкой позиций команд i8080 (не Z80) в поисках оптимального. Думаете, от перестановки кодового соответствия практически ничего не меняется? Это - не так и после немногих раздумий я присвоил операции RET код FF, чтобы получить трюковую операцию условного возврата из подпрограммы через замыкание команды условного относительного перехода на свой собственный аргумент. Тем самым, появился набор команд условного возврата через трюк замыкания, не затрачивая ячейки таблицы команд…
Так как мой процессор должен иметь дружественную систему команд, интуитивно лёгкую к запоминанию для ручного программирурования машинного кода в спартанских условиях (ассемблер ещё не был готов), большинство операций занимают в таблице позиции с интуитивно прозрачными позициями: A0-AF - ALU, B0-BF - Branch, C0-CF - inCrement, D0-DF - Decrement, E0-EF - Exchange, F0-FF - Functions…
Спустя несколько месяцев упорной работы был худо-бедно написан ассемблер и дизассемблер. Трудность была в том, что когда я вносил поправку в систему команд, требовалось вносить и модификации в ассемблер. Но, потом я решение нашёл посредством создания нескольких структурных массивов. Вся система команд описывается сотнюю строк дешифратора в стиле постулатов Verilog: 0-1-X. Что существенно упростило дальнейщую разработку. На данный момент дешифратор имеет шину из 18 разрядов. Что примерно около 4 миллионов команд. Конечно, команд у меня гораздо меньше. Так как группами битов просто указывается при какой ситуации состояния процессора и даже АЛУ команда распознаётся дешифратором…
Следует указать ещё один любопытный момент. Было давно замечено, что АЛУ неспособно выставлять флажки процессора ни при каких обстоятельствах в три комбинации: Ноль со знаком (SF+ZF), ноль с нечётным паритетом (PF+ZF) и ноль со знаком нечётного паритета (SF+PF+ZF). Так как это попросту не вписывается в таблицу постулатов работы вычислительных узлов. Тем самым, в своей архитектуре процессора я это использовал на уровне самого дешифратора команд. И эти три неиспользуемых комбинации флажков статуса процессора несколько расширили возможности системы команд. Появилась возможность повтора одной инструкции несколько раз (аналог x86-REP) и возможность линейного пропуска нескольких операций без ветвления (аналог x86-CMOVcc). Инструкции получили мнемонику LOOP и SKIP соответственно…
Третья же комбинация флажков (SF+PF+ZF) не имеет прямой инструкции и достигается трюковым ветвлением с замыканием на себя (не аргумент FF, а на код операции JMP). Так как я свой процессор пытаюсь сделать хоть не умным, но адекватным, то замыкание на бесконечный цикл является трюковой операцией WAIT - аналог LOOP, но с условным выполнением: Без установленного флага CF цикл не работает (нечто сходное с x86-REPNZ)…
Команды работы с портами ввода/вывода IN/OUT давно называют костылями пережитков стародавних архитектур. И в системе команд моего процессора они явно отсутствуют. Хотя и имеются через трюковой WAIT-цикл. И это не просто так. Когда внешнее устройство готово, WAIT-цикл продолжается всего одну итерацию. А если устройство занято, WAIT-цикл займёт от 7 до 255 итераций. И программа сразу будет знать, устройство готово или занято, так как в этом случае IN/OUT изменяют флаг CF…
Процессором имеется всего 10 команд программного прерывания INT 0-9 с машинным кодом F0-F9 соответственно (Fn0-Fn9). В комбинации в WAIT-цикле эти INT-инструкции творят чудеса: Дешифратор команд отключается от внешней шины адреса/данных и подключается к внутреннему буферу команд, в котором можно запомнить до 7 инструкций. Внутри WAIT-цикла INT-инструкция заставляет дешифратор команд читать инструкции только внутреннего буфера, которые, естественно, способны выполняться за 1 такт. Тем самым, получается подобие макроса или гибкой микрокоманды, которая выполняется условным циклом до 255 раз. Программируется INT-прошивка так же легко - инструкцией SKIP: Все пропускаемые дешифратором операции попадают во внутренний буфер…
Аппаратные прерывания процессор явно обрабатывать не умеет. Архитектурно всё задумано так, чтобы система на базе данного процессора была мультизадачной. Аппаратно процессор имеет 128 регистровых файла, каждый из которых имеет объём до 256 слов, несущий в себе значения всех РОН, указателей и счётчиков. Тем самым, процессор способен мгновенно переключать контексты задач. При этом, после запуска процессор начинает выполнять задачу с нулевым контекстом, предоставляя ей привелегии ядра системы. Внутри кода этого ядра операции WAIT+IN/OUT, например, работают с портами напрямую, как и должно быть. Но в контексте прикладных задач подобные комбинации просто являются переключателями на контекст ядра и не позволяет вторичному кода программировать периферию напрямую. То же самое происходит и с аппаратными прерываниями, которые просто откидывают контекст задачи до ядра, где уже и выполняется соответствующая обработка. Следует отметить то, что инструкция HLT внутри кода ядра работает как единственный особый префикс, управляющий переключателем контекстов задач. Говоря проще, ядро передаёт управление прикладному коду посредством комбинации WAIT+HLT на время, после чего в авто-режиме SKIP пропускает до 7 следующих команд JMP (напоминает ON n GOTO Бейсика) в соответствии с ситуацией. Ситуаций всего бывает 8: запрос к API, программное прерывание, сбой страниц памяти, истечение кванта времени выполнения конкретной задачи, попытка доступа к порту ввода/вывода, программная ошибка вычислений, внешнее прерывание, приход сигнала Reset.
После запуска системы выполняется, естественно, ситуация с Reset. Причём, если сигнал Reset приходит позднее, процессор не сбрасывается, а передаёт управление контексту ядра, которое должно адекватно успеть совершить соответствующие действия. Если ядро не смогло обработать это событие или повисло, с обнулением счётчика тактов процессор сбрасывается в исходное состояние…
Таким образом, в 18-разрядной шиной дешифратора команд 8 разрядов выделяется собственно под код самой команды. Три бита - код префикса команды. Один бит - признак трюкового замыкания, когда непосредственный байт аргумента команды равен -1 (FF). Ещё три бита - расширенние дешифрации команд флагами процессора (LOOP/WAIT/EVAL + бит Boot-mode). Оставшиеся три бита не играют особой роли и нежны лишь для сцепления смежных байт-кодов (F0-F7 + F8-F9; FA-FD / EA-ED; префиксов с восходящим/нисходящим/прямым замыканием и т.д.).
После появления напряжения питания процессор оказывается в состоянии "холодного старта". В этом состоянии он не реагирует на сигналы генератора тактовой частоты и все его шины находятся в высокоимпендансном состоянии. С приходом сигнала "сброса" счётчик тактов должен отсчитать 65536 запускающих тактовых импульсов, прежде чем процессор запустится. Если на протяжении всего запускающего периода уровень сигнала "сброса" не изменялся, всё процессорное устройство включается в стандартный рабочий режим. Иначе счётчик запускающих тактов обнуляется вновь. Такой усложнённый алгоритм старта был введён с целью обезопасить операционную среду от разных нелинейных ситуаций.
Во время действия операционной среды исключаются случайные возможности со сбросом системы в исходное состояние приходом кратковременного сигнала "сброса". Как и при "холодном старте", перезапуск состоится не ранее отсчёта 65536 тактовых импульсов. За исключением того, что сам код ядра может влиять на отсчёт запускающего периода и откладывать его на неопределённый срок. Тем не менее, если вся система зависла и не откликается на внешние сигналы, сигнал "сброса" достаточной продолжительности произведёт перезапуск процессорного устройства в исходное состояние…
Так как флажки состояние процессора изменяются не только АЛУ, но и тесно связаны с дешифратором команд, флаг CF используется как опциональный не только в WAIT-циклах, но и при поступлении какого-либо события в системе. Так, на флаг CF влияет как фронт, так и срез сигнала "сброса", достаточно информируя о всех факторах.
Помимо контекстных файлов процессорное устройство имеет 8 управляющих регистром, доступные для чтения во всех прикладных задачах. Приложение может свободно прочитать и основной нулевой регистр с индексом собственного контекста в среде, а также счётчик оставшихся тактов до момента передачи управления другой задаче в очереди. Однако, для записи в эти 7 регистров приложению необходимо неявно сгенерировать обращение к ядру с ожиданием. Нулевой управляющий регистр со стороны приложения для записи явно не представлен никак, так как доступ к нему является инструкцией останова HLT…
Следует заметить, что холостых операций в процессоре всего 8. Одна из которых имеет код FE, а остальные 7 - её префикс-расширенные модификации. Все они действительно гарантируют задержку на указаное число тактов. В составе с LOOP можно ставить в программах точки с управляемой задержкой. Тогда как в составе с WAIT эти NOP/1-7 несут свободный смысл и могут уведомлять операционную среду о возможной паузе в прикладном процессе без необходимости возвращаться к нему некоторый период времени или о снижении приоритета задачи в очереди. Особо следует также отметить сочетание WAIT+HLT и LOOP+HLT, означающие явное завершение того или иного действия. Так, LOOP+HLT может означать прекращение работы конкретного процесса. Тогда как WAIT+HLT свидетельствует о необходимости выдачи ожидаемого ресурса от системы за неопределённый период. Как пример, процедура перерисовки указателя мыши требует обязательного прихода уведомления о смене позиции на экране или какого-либо другого действия, что может укладываться в довольно продолжительный интервал времени в периоде ожидания действий пользователя…
Вот краткое и не документабельное изложение сути поставленной мной задачи. Выполняю всё в одиночку, медленно, сердито и скудно. Был бы рад энтузиастам, готовым подключиться к проработке некоторых ньюансов проекта.
Страничка проекта с эмулятором под Chrome - в окне эмулятора:
F1 - 1 шаг эмуляции;
F4 - запуск автоэмуляции;
Alt+1..7 - выбор префикса в таблице команд;
Alt+8..0 - трюковые префиксы INT/LOOP/WAIT;
Alt+K - буфер клавиатуры;
Alt+P,T,R - поле адреса/транслятора/управления соответственно.
P.S.: Принимается адекватная критика.
Eщё будучи школьником, когда разобрался более-менее в основах работы микропроцессора РАДИО-86РК и открыл, что все сигналы, за исключением выводов частота/ожидание/прерывание/сброс, генерирует сам процессор по мере надобности, начались предприниматься попытки разработки собственного идеального процессора. Конечно, опираясь на опыт работы с ИК80, а позднее - и Z80…
В первую очередь, всегда мною предпринималась попытка разработать идеальную таблицу команд, не требующей существенных усилий для запоминания соответствий машинного кода к мнемонике и самой операции. Что стало моей идеалогией. Так, например, меня возмутило, что в i8086 коду 00 соответствует операция ADD, что сбивает с толку, если память обнулена. В поисках стабильности и защиты от сбоев, коду 00 я навсегда в своих набросках присвоил операцию останова HLT. И это вполне здравое решение.
Когда начал практически разрабатывать эмулятор, пришёл к выводу, что команды условного возврата из подпрограммы - нужные, но излишние в таблице. Система команд x86 изобилует реликтовым хламом, который зря захламляет всё и отжирает драгоценный байт-код: AAA, AAD, AAM, AAS. Команды ENTER/LEAVE используются при входе в подпрограмму и возврате из неё, т.е. не достаточно часто. Честно говоря, было много вариантов с перестановкой позиций команд i8080 (не Z80) в поисках оптимального. Думаете, от перестановки кодового соответствия практически ничего не меняется? Это - не так и после немногих раздумий я присвоил операции RET код FF, чтобы получить трюковую операцию условного возврата из подпрограммы через замыкание команды условного относительного перехода на свой собственный аргумент. Тем самым, появился набор команд условного возврата через трюк замыкания, не затрачивая ячейки таблицы команд…
Так как мой процессор должен иметь дружественную систему команд, интуитивно лёгкую к запоминанию для ручного программирурования машинного кода в спартанских условиях (ассемблер ещё не был готов), большинство операций занимают в таблице позиции с интуитивно прозрачными позициями: A0-AF - ALU, B0-BF - Branch, C0-CF - inCrement, D0-DF - Decrement, E0-EF - Exchange, F0-FF - Functions…
Спустя несколько месяцев упорной работы был худо-бедно написан ассемблер и дизассемблер. Трудность была в том, что когда я вносил поправку в систему команд, требовалось вносить и модификации в ассемблер. Но, потом я решение нашёл посредством создания нескольких структурных массивов. Вся система команд описывается сотнюю строк дешифратора в стиле постулатов Verilog: 0-1-X. Что существенно упростило дальнейщую разработку. На данный момент дешифратор имеет шину из 18 разрядов. Что примерно около 4 миллионов команд. Конечно, команд у меня гораздо меньше. Так как группами битов просто указывается при какой ситуации состояния процессора и даже АЛУ команда распознаётся дешифратором…
Следует указать ещё один любопытный момент. Было давно замечено, что АЛУ неспособно выставлять флажки процессора ни при каких обстоятельствах в три комбинации: Ноль со знаком (SF+ZF), ноль с нечётным паритетом (PF+ZF) и ноль со знаком нечётного паритета (SF+PF+ZF). Так как это попросту не вписывается в таблицу постулатов работы вычислительных узлов. Тем самым, в своей архитектуре процессора я это использовал на уровне самого дешифратора команд. И эти три неиспользуемых комбинации флажков статуса процессора несколько расширили возможности системы команд. Появилась возможность повтора одной инструкции несколько раз (аналог x86-REP) и возможность линейного пропуска нескольких операций без ветвления (аналог x86-CMOVcc). Инструкции получили мнемонику LOOP и SKIP соответственно…
Третья же комбинация флажков (SF+PF+ZF) не имеет прямой инструкции и достигается трюковым ветвлением с замыканием на себя (не аргумент FF, а на код операции JMP). Так как я свой процессор пытаюсь сделать хоть не умным, но адекватным, то замыкание на бесконечный цикл является трюковой операцией WAIT - аналог LOOP, но с условным выполнением: Без установленного флага CF цикл не работает (нечто сходное с x86-REPNZ)…
Команды работы с портами ввода/вывода IN/OUT давно называют костылями пережитков стародавних архитектур. И в системе команд моего процессора они явно отсутствуют. Хотя и имеются через трюковой WAIT-цикл. И это не просто так. Когда внешнее устройство готово, WAIT-цикл продолжается всего одну итерацию. А если устройство занято, WAIT-цикл займёт от 7 до 255 итераций. И программа сразу будет знать, устройство готово или занято, так как в этом случае IN/OUT изменяют флаг CF…
Процессором имеется всего 10 команд программного прерывания INT 0-9 с машинным кодом F0-F9 соответственно (Fn0-Fn9). В комбинации в WAIT-цикле эти INT-инструкции творят чудеса: Дешифратор команд отключается от внешней шины адреса/данных и подключается к внутреннему буферу команд, в котором можно запомнить до 7 инструкций. Внутри WAIT-цикла INT-инструкция заставляет дешифратор команд читать инструкции только внутреннего буфера, которые, естественно, способны выполняться за 1 такт. Тем самым, получается подобие макроса или гибкой микрокоманды, которая выполняется условным циклом до 255 раз. Программируется INT-прошивка так же легко - инструкцией SKIP: Все пропускаемые дешифратором операции попадают во внутренний буфер…
Аппаратные прерывания процессор явно обрабатывать не умеет. Архитектурно всё задумано так, чтобы система на базе данного процессора была мультизадачной. Аппаратно процессор имеет 128 регистровых файла, каждый из которых имеет объём до 256 слов, несущий в себе значения всех РОН, указателей и счётчиков. Тем самым, процессор способен мгновенно переключать контексты задач. При этом, после запуска процессор начинает выполнять задачу с нулевым контекстом, предоставляя ей привелегии ядра системы. Внутри кода этого ядра операции WAIT+IN/OUT, например, работают с портами напрямую, как и должно быть. Но в контексте прикладных задач подобные комбинации просто являются переключателями на контекст ядра и не позволяет вторичному кода программировать периферию напрямую. То же самое происходит и с аппаратными прерываниями, которые просто откидывают контекст задачи до ядра, где уже и выполняется соответствующая обработка. Следует отметить то, что инструкция HLT внутри кода ядра работает как единственный особый префикс, управляющий переключателем контекстов задач. Говоря проще, ядро передаёт управление прикладному коду посредством комбинации WAIT+HLT на время, после чего в авто-режиме SKIP пропускает до 7 следующих команд JMP (напоминает ON n GOTO Бейсика) в соответствии с ситуацией. Ситуаций всего бывает 8: запрос к API, программное прерывание, сбой страниц памяти, истечение кванта времени выполнения конкретной задачи, попытка доступа к порту ввода/вывода, программная ошибка вычислений, внешнее прерывание, приход сигнала Reset.
После запуска системы выполняется, естественно, ситуация с Reset. Причём, если сигнал Reset приходит позднее, процессор не сбрасывается, а передаёт управление контексту ядра, которое должно адекватно успеть совершить соответствующие действия. Если ядро не смогло обработать это событие или повисло, с обнулением счётчика тактов процессор сбрасывается в исходное состояние…
Таким образом, в 18-разрядной шиной дешифратора команд 8 разрядов выделяется собственно под код самой команды. Три бита - код префикса команды. Один бит - признак трюкового замыкания, когда непосредственный байт аргумента команды равен -1 (FF). Ещё три бита - расширенние дешифрации команд флагами процессора (LOOP/WAIT/EVAL + бит Boot-mode). Оставшиеся три бита не играют особой роли и нежны лишь для сцепления смежных байт-кодов (F0-F7 + F8-F9; FA-FD / EA-ED; префиксов с восходящим/нисходящим/прямым замыканием и т.д.).
После появления напряжения питания процессор оказывается в состоянии "холодного старта". В этом состоянии он не реагирует на сигналы генератора тактовой частоты и все его шины находятся в высокоимпендансном состоянии. С приходом сигнала "сброса" счётчик тактов должен отсчитать 65536 запускающих тактовых импульсов, прежде чем процессор запустится. Если на протяжении всего запускающего периода уровень сигнала "сброса" не изменялся, всё процессорное устройство включается в стандартный рабочий режим. Иначе счётчик запускающих тактов обнуляется вновь. Такой усложнённый алгоритм старта был введён с целью обезопасить операционную среду от разных нелинейных ситуаций.
Во время действия операционной среды исключаются случайные возможности со сбросом системы в исходное состояние приходом кратковременного сигнала "сброса". Как и при "холодном старте", перезапуск состоится не ранее отсчёта 65536 тактовых импульсов. За исключением того, что сам код ядра может влиять на отсчёт запускающего периода и откладывать его на неопределённый срок. Тем не менее, если вся система зависла и не откликается на внешние сигналы, сигнал "сброса" достаточной продолжительности произведёт перезапуск процессорного устройства в исходное состояние…
Так как флажки состояние процессора изменяются не только АЛУ, но и тесно связаны с дешифратором команд, флаг CF используется как опциональный не только в WAIT-циклах, но и при поступлении какого-либо события в системе. Так, на флаг CF влияет как фронт, так и срез сигнала "сброса", достаточно информируя о всех факторах.
Помимо контекстных файлов процессорное устройство имеет 8 управляющих регистром, доступные для чтения во всех прикладных задачах. Приложение может свободно прочитать и основной нулевой регистр с индексом собственного контекста в среде, а также счётчик оставшихся тактов до момента передачи управления другой задаче в очереди. Однако, для записи в эти 7 регистров приложению необходимо неявно сгенерировать обращение к ядру с ожиданием. Нулевой управляющий регистр со стороны приложения для записи явно не представлен никак, так как доступ к нему является инструкцией останова HLT…
Следует заметить, что холостых операций в процессоре всего 8. Одна из которых имеет код FE, а остальные 7 - её префикс-расширенные модификации. Все они действительно гарантируют задержку на указаное число тактов. В составе с LOOP можно ставить в программах точки с управляемой задержкой. Тогда как в составе с WAIT эти NOP/1-7 несут свободный смысл и могут уведомлять операционную среду о возможной паузе в прикладном процессе без необходимости возвращаться к нему некоторый период времени или о снижении приоритета задачи в очереди. Особо следует также отметить сочетание WAIT+HLT и LOOP+HLT, означающие явное завершение того или иного действия. Так, LOOP+HLT может означать прекращение работы конкретного процесса. Тогда как WAIT+HLT свидетельствует о необходимости выдачи ожидаемого ресурса от системы за неопределённый период. Как пример, процедура перерисовки указателя мыши требует обязательного прихода уведомления о смене позиции на экране или какого-либо другого действия, что может укладываться в довольно продолжительный интервал времени в периоде ожидания действий пользователя…
Вот краткое и не документабельное изложение сути поставленной мной задачи. Выполняю всё в одиночку, медленно, сердито и скудно. Был бы рад энтузиастам, готовым подключиться к проработке некоторых ньюансов проекта.
Страничка проекта с эмулятором под Chrome - в окне эмулятора:
F1 - 1 шаг эмуляции;
F4 - запуск автоэмуляции;
Alt+1..7 - выбор префикса в таблице команд;
Alt+8..0 - трюковые префиксы INT/LOOP/WAIT;
Alt+K - буфер клавиатуры;
Alt+P,T,R - поле адреса/транслятора/управления соответственно.
P.S.: Принимается адекватная критика.
- Вложения
-
- 0_7x80.gif
- Система команд процессора
+ 7 плоскостей префиксированных инструкций - (177.97 KiB) Скачиваний: 483
Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 20:16:25
Критика говорите ? Ну ладно, так и быть - "по просьбам трудящихся" .. 
Ежели прочитать всё таки Вашу "нетленку" (, в школолошной среде многовероятно было бы обзываемо "многабукаффниасил" ) ,то ..
.. обнаружится , что слово "архитектура", гордо написанное в заголовке, к изложенному имеет отдалённое и опосредованное отношение.
Вы , сударь, резко ударились в мелочи, по которым можно лишь смутно догадываться об этой самой архитектуре.
Добрый совет : раз уж сказали "А(рхитектура)" , то приведите (так, для тех, кто вдруг не в курсе) определение этого самого понятия, нарисуйте "Б(лок-схему)" Вашего гипотетического процессора, укажите основные потоки В(вода) и В(ывода) данных - т.е по каким шинам и как они передаются, отметьте принадлежит ли Ваша "архитектура" к типу "Г(арвардской)" или ещё какой, нарисуйте ну хотя бы примерные предполагаемые временные Д(иаграммы) , и т.д - а уж потом мелочи и детали в т.ч всякие трюки и особенности .
Как то так .. Тогда и будет что обсуждать по существу.
Ежели прочитать всё таки Вашу "нетленку" (, в школолошной среде многовероятно было бы обзываемо "многабукаффниасил" ) ,то ..
.. обнаружится , что слово "архитектура", гордо написанное в заголовке, к изложенному имеет отдалённое и опосредованное отношение.
Вы , сударь, резко ударились в мелочи, по которым можно лишь смутно догадываться об этой самой архитектуре.
Добрый совет : раз уж сказали "А(рхитектура)" , то приведите (так, для тех, кто вдруг не в курсе) определение этого самого понятия, нарисуйте "Б(лок-схему)" Вашего гипотетического процессора, укажите основные потоки В(вода) и В(ывода) данных - т.е по каким шинам и как они передаются, отметьте принадлежит ли Ваша "архитектура" к типу "Г(арвардской)" или ещё какой, нарисуйте ну хотя бы примерные предполагаемые временные Д(иаграммы) , и т.д - а уж потом мелочи и детали в т.ч всякие трюки и особенности .
Как то так .. Тогда и будет что обсуждать по существу.
Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 20:34:15
У меня иногда бывали "размышления на унитазе" по поводу декодера команд для процессора. Суть заключалась в том, что в команде должны быть выделены биты признака чтения\записи, обращения к АЛУ, к памяти, к регистрам и т.д. Остальные биты уже представляют номер команды. Допустим, биты обращения можно связать с шиной управления мультиплексором, который мультиплексирует биты номера команды к тому или иному узлу, имеющему свой декодер. Тот уже забирает операнды и производит операцию. Имея запас по битам обращения, процессор можно доращивать различными сопроцессорами и добавлять новые инструкции. Если одна инструкция вместе с операндами влезает в разрядность процессора, то помимо мультиплекирования номера команды, можно мультиплексировать и сами операнды. В итоге инструкция имеет шансы выполниться за такт. Данный подход упрощает декодер команд и дает возможность к дальнейшей модернизации.
Но это просто мысли с наскоку. Может там найдутся и подводные камни.
Имел бы FPGAху под рукой, может быть что-нибудь и попробовал бы реализовать.
Но это просто мысли с наскоку. Может там найдутся и подводные камни.
Имел бы FPGAху под рукой, может быть что-нибудь и попробовал бы реализовать.
Микропроцессоры: "размышления на унитазе" об улучшайзинге
Чт янв 12, 2017 20:41:12
*_Подходящий эпитет.DX168B писал(а):.. "размышления на унитазе"* ..
.. И инструкция имеет шансы выполниться за такт**. Данный подход ...
**_И , как это ни скучно, но "всё уже придумано до нас и без нас" - вполне N-ное число лет уже вовсю клепают "однотактовое ядро" для некоторых архитектур.
Микропроцессоры: Попытки разработки собственной архитектуры
Чт янв 12, 2017 20:59:26
Работaющий эмулятор и запускаемая программа "Монитор" (BIOS ) - думал, что более, чем достаточно, чтобы показать, что задумку воплотил. Пусть даже пока в HTML5+JS.
В исходнике увидите следующий блок:
А насчёт архитектуры. Наверное, я сильно ошибаюсь, раз читаю достаточно резкую критику в сторону этого термина моей стороны.
Если я не очень ошибаюсь, именно архитектурой ВМ80 описывалось, что все арифметико-логические действия производятся с аккумулятором; что имеется поддержка до 256 УВВ; что максимально адресуемое пространство - 64кб; что поддерживается прямая и косвенная адресация…
Извиняюсь, но разве я не достаточно уделил внимания этим деталям?
P.S.: Благодарю за критику. Буду исправлять (описание Архитектуры ) …
В исходнике увидите следующий блок:
- Код:
+----------=> $L:Lock-mask
| +----------=> $K:Keep code
| | +---------=> $Z:PREFIX #Z
| | | +-------=> $J:
| | | | +-----=> $Y:
| | | | | +---=> $I:
| | | | | | +-=> $X:
| | | | | | |
/|\/|\/|\|/|\|/|\
LLLKKKZZZJYYYIXXX_
XXX00000000000C HLT :IS_BOOT ? IS_WAIT ? CR(0, ACC( ) ) : FH(8 ) : (CR(CR(0 ) & 0xF0 ) , FH(0xB ) , FL(0x5 ) ) // Halting
XXX00011111110C NOP :$IB==$IB // No operation
0000000XXX0XXX_ PREFIX R#X/P#X :0 // Prefix for R#X!/P#X!
X1000011101XXXE PUSH+ U#X :HEAP(U#X( ) ) // Push pointer into stack
X1000011111XXXE POP+ U#X :U#X(HEAP( ) ) // Pop pointer from stack
XXXXXX11111110C NOP #Z :#Z // Hollow operation through #Z ticks
XXX10010101XXXA ALU#X IB :$1=ALU#X(DROP(FH( ) ) ,$IB ) ,ACC($1 ) ,FL($1.hi( ) ) // ALU#X! with retained and immediate
XXXXXX10101XXXA ALU#X Z#Z,IB :$1=ALU#X(Z#Z( ) ,$IB ) ,Z#Z($1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Z! and byte
XXX1000XXX1XXXA ALU#X Z#Y :$1=ALU#X(DROP(#Y ) ,REG(#Y ) ) ,REG(#Y,$1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Y! and retained
XXXXXX0XXX1XXXA ALU#X Z#Z,R#Y :$1=ALU#X(Z#Z( ) ,R#Y( ) ) ,Z#Z($1 ) ,FL($1.hi( ) ) // ALU#X! with Z#Z! and R#Y!
000XXX0XXX0XXXC HLT #Z :IS_BOOT && IS_WAIT ? FH( ) ==(#Z+8 ) ? ACC(PORT(ACC( ) ) ) : FH( ) >=8 ? PORT(R#Z( ) ,ACC( ) ) : CR(#Z,ACC( ) ) : FH(#Z+8 ) // Hold #Z index number
X1000011001XXXD INC+ Q#X :Q#X(Q#X( ) +1 ) // Increment Q#X!
X1000011011XXXD DEC+ Q#X :Q#X(Q#X( ) -1 ) // Decrement Q#X!
XXX00011001111A CMC :FL(FL( ) ^ 2 ) // Complement carry flag
XXXXXX11001110D ADC BX,T#Z :$1=BX( ) +T#Z( ) +(_CF?1:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , BX($1 ) // Addition register pair with carry
X10XXX11001XXXD ADD Q#X,T#Z :$1=Q#X( ) +T#Z( ) +(_CF?0:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , Q#X($1 ) // Addition register pair
XXXXXX11011110D SBB BX,T#Z :$1=BX( ) -T#Z( ) -(_CF?1:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , BX($1 ) // Subtraction register pair with borrow
X10XXX11011XXXD SUB Q#X,T#Z :$1=Q#X( ) -T#Z( ) -(_CF?0:0 ) ,$2=($1>>15 ) &2,FL((FL( ) & 0xD ) |$2 ) , Q#X($1 ) // Subtraction register pair
XXX00011001010A XCHG :$1=ACC( ) ; for($2=0,$0=0;$0<8;++$0,$1>>=1 ) $2=($2<<1 ) +($1&1 ) ; ACC($2 ) >0 // Exchange retained bits by mirror
XXXXXX11001010A XCHG P#Z :$1=DST( ) ,DST(P#Z( ) ) ,P#Z($1 ) // Exchange P#Z! with retained pair
XXXXXX11001111A XCHG R#Z :$1=ACC( ) ,ACC(R#Z( ) ) ,R#Z($1 ) // Exchange R#Z! with retained register
XXX100110X1XXXA ALU#W :$1=ACC(ALU#W(ACC( ) ) ) ,FL($1.hi( ) ) // ALU#W! with retained
XXXXXX110X1XXXA ALU#W Z#Z :$1=Z#Z(ALU#W(Z#Z( ) ) ) ,FL($1.hi( ) ) // ALU#W! with Z#Z!
X111000XXX0000A MUL R#Y :0 //
X1110000000XXXF XCHG R#X :$1=ACC( ) ,ACC(R#X( ) ) ,R#X($1 ) // Exchange R#Z! with retained register
X111000XXX0100F XCHG P#Y :$1=DST( ) ,DST(P#Y( ) ) ,P#Y($1 ) // Exchange P#Z! with retained pair
X111000XXX0XXXF MOV P#X,T#Y :P#X(T#Y( ) ) // Move T#Y! vector to P#X!
01110000000XXXD_PUSH+ T#X+[T#Y] :HEAP(T#X( ) +DW(T#Y( ) ) ) // Correct effective address in stack
0111000XXX0XXXD_PUSH+ T#X+T#Y :HEAP(T#X( ) +T#Y( ) ) // Push effective address into stack
1111000XXX0000D_PUSH+ [T#X]-T#Y :HEAP(HEAP( ) -T#Y( ) ) // Correct effective address in stack
1111000XXX0XXXD_PUSH+ T#X-T#Y :HEAP(T#X( ) -T#Y( ) ) // Push effective address into stack
XXXXXX00000000C HLT R#Z :IS_WAIT ? FH( ) == #Z ? ACC(CTX(ACC( ) ) ) : $IR ? CTX(ACC( ) ,R#Z( ) ) : R#Z(CR(FH( ) ) ) : FH(#Z ) // Hold R#Z!/P#Z! as retained
XXX0000XXX0XXXF MOV R#X,R#Y :IS_WAIT && true ? #Y == 0 ? ($1=PORT(R#X( ) ) ,trace.eady?R#X($1 ) :0 ) : PORT(R#X( ) ,R#Y( ) ) : R#X(R#Y( ) ) // Move R#Y! data into R#X!
X11XXX0XXX0XXXD_ALU#Z P#X,T#Y :0 //
XXX00010110000B JCND#X $+IB :CND#X?IP(IP( ) +$IV ) :0 // Relative branching if CND#X!
XXX00010100XXXF MOV R#X,IB :R#X($IB ) // Move immediate data into R#X!
XXX00010110001E BIAS $+IB :HEAP($IP+$IV ) // Push instruction based relative address
XXX00010110XXXB CCND#X $+IB :CND#X?HEAP(IP( ) ) +IP(IP( ) +$IV ) :0 // Relative call if CND#X!
XXX00011000XXXA INC+ R#X :$1=ADD(R#X( ) ,1 ) ,R#X($1 ) ,FL($1.hi( ) ) // Increment R#X!
XXX00011010XXXA DEC+ R#X :$1=SUB(R#X( ) ,1 ) ,R#X($1 ) ,FL($1.hi( ) ) // Decrement R#X!
X00XXX1111XXXXB INT #T :HEAP($IP ) +IP(JP(#T<10?0:1 ) ) >0 // Programm interruption indexed by #T
XXX10011101110F XCHG [SP] :$1=DST( ) ,DST(DW($2=SP( ) ) ) , DW($2, $1 ) // Exchange retained pair with stack heap
XXXXXX11101110F XCHG P#Z,[SP] :$1=P#Z( ) ,P#Z(DW(SP( ) ) ) , DW(SP( ) , $1 ) // Exchange pair P#Z with stack heap
001XXX0XXX0XXXF XCHG P#Z,P#Y :$1=P#Z( ) ,P#Z(P#Y( ) ) ,P#Y($1 ) // Exchange P#Z! and P#Y!
010XXX0XXX0XXXF XCHG R#Z,R#Y :$1=R#Z( ) ,R#Z(R#Y( ) ) ,R#Y($1 ) // Exchange R#Z! and R#Y!
011XXX0XXX0XXXD LEA P#Z,T#X+T#Y :P#Z(T#X( ) +T#Y( ) ) // Load T#X!+T#Y! effective address into P#Z
111XXX0XXX0XXXD LEA P#Z,T#X-T#Y :P#Z(T#X( ) -T#Y( ) ) // Load T#X!-T#Y! effective address into P#Z
XXXXXX10100000E POP+ [P#Z+IB] :DW(P#Z( ) +$IV,HEAP( ) ) // Pop data into memory indexed by P#Z
XXXXXX10100XXXF MOV R#X,[P#Z+IB] :trace.is_port=IP_BP; trace.is_context=IP_SP; R#X(DB(P#Z( ) +$IV ) ) // Move memory data by P#Z pointer into R#X
XXXXXX10110000E PUSH+ [P#Z+IB] :HEAP(DW(P#Z( ) +$IV ) ) // Push data from memory indexed by P#Z
XXXXXX10110XXXF MOV [P#Z+IB],R#X :trace.is_port=IP_BP; trace.is_context=IP_SP; DB(P#Z( ) +$IV,R#X( ) ) // Move R#X register data into memory by P#Z
XXX10011101111E PUSH :HEAP(DST( ) ) // Push retained pair
XXXXXX11101111E PUSH+ S#Z :HEAP(S#Z( ) ) // Push service S#Z register pair to stack
XXX10011111111E POP :DST(HEAP( ) ) // Pop retained pair
XXXXXX11111111E POP+ S#Z :S#Z(HEAP( ) ) // Pop service S#Z register pair from stack
XXXXXX11101010E PUSH+ R#Z :DUP(#Z ) // Dup R#Z register history
XXXXXX11101011C SKIP [R#Z] :FH(R#Z( ) |8 ) ,FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by R#Z bits
XXXXXX11101100C SKIP R#Z :FH(#Z ) , FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by R#Z counter
XXXXXX11101101C SKIP #Z :FH(#Z | 8 ) , FL((FL( ) & 0x02 ) | 0x05 ) // Exclude next operations by #Z times
XXXXXX11111010E POP+ R#Z :DROP(#Z ) // Drop R#Z register history
XXXXXX11111011C LOOP [R#Z] :FH(R#Z( ) |8 ) ,FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by R#Z bits
XXXXXX11111100C LOOP R#Z :FH(#Z ) , FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by R#Z counter
XXXXXX11111101C LOOP #Z :FH(#Z | 8 ) , FL((FL( ) & 0x02 ) | 0x09 ) // Forcing next operation by #Z times
XXXXXX100XXXXXE PUSH+ #VIB :HEAP(0x#V00 + $IB ) // Push immediate data into stack
0XX10010111XXXX --- IB :return 0 // Reserved extended code
XXX10010111010E LEA +IB :DST(DST( ) +$IB ) // Load retained effective address
X1010010111XXXF MOV [U#X],IB :DB(U#X( ) ,$IB ) // Load immediate data into memory by U#X
XXXXXX10111000B JMP $+#UIB :$IW==-2?(FL((FL( ) & 0x02 ) | 0x0D ) ,trace.expression=0 ) :IP(IP( ) +$IW ) // Unonditional relative branching
XXXXXX10111001B CALL $+#UIB :$IW==-2?0:HEAP(IP(IP( ) +$IW ) ) // Unconditional relative call
XXXXXX10111XXXB JCND#X $+#UIB :CND#X?IP(IP( ) +$IW ) :0 // Branching if CND#X!
XXXXXXXXXXXXXXX --- :return 0 // Reserved code
А насчёт архитектуры. Наверное, я сильно ошибаюсь, раз читаю достаточно резкую критику в сторону этого термина моей стороны.
Если я не очень ошибаюсь, именно архитектурой ВМ80 описывалось, что все арифметико-логические действия производятся с аккумулятором; что имеется поддержка до 256 УВВ; что максимально адресуемое пространство - 64кб; что поддерживается прямая и косвенная адресация…
Извиняюсь, но разве я не достаточно уделил внимания этим деталям?
P.S.: Благодарю за критику. Буду исправлять (описание Архитектуры ) …
Re: Микропроцессоры: "размышления на унитазе" об улучшайзинг
Чт янв 12, 2017 21:01:55
petrenko писал(а):И , как это ни скучно, но "всё уже придумано до нас и без нас" - вполне N-ное число лет уже вовсю клепают "однотактовое ядро" для некоторых архитектур.
И как ни странно, такие мысли бывают полезными для саморазвития.
И всетаки мне интересно было бы поболтать о процессоростроительстве.
Поясню свою идею: Допустим, наша инструкция является восьмибитной. Делим ее на две части. На две тетрады к примеру.
Младшая тетрада представляет собой адрес узла, которому будет передана старшая тетрада команды, представляющая собой номер команды.
Этому же узлу сразу же можно передать и операнды.
Получаем следующую модель работы.
Происходит первый такт.
Из памяти забирается инструкция с операндами и заносится в регистр команды.
Как она туда попадает, мультиплексор подключает оставшиеся выходы (кроме выходов младшей тетрады команды ) регистра команды, согласно содержимому младшей тетрады, к соответствующему узлу. Тот имеет свои регистры-защелки на входе и полученные данные фиксируются в них.
Происходит второй такт.
Узел выполняет команду, а в регистр команды заносится следующая инструкция из ПЗУ.
Можно сделать регистр команд в виде FIFO буфера, чтобы не стопориться на выполнении многотактных команд. Можно этот "конвейер" реализовать в виде нескольких регистров команд, чтобы выполнять заранее какие-нибудь подготовительные действия перед выполнением, в зависимости от попавших инструкций в FIFO буфер.
Микропроцессоры: "размышления на унитазе" об улучшайзинге
Чт янв 12, 2017 21:28:29
petrenko писал(а):И , как это ни скучно, но "всё уже придумано до нас и без нас" - вполне N-ное число лет уже вовсю клепают "однотактовое ядро" для некоторых архитектур.
*_Соверешенно верно ! Именно для самообучения - наилучшим образом ! Ну и ещё можно для досуговых целей тож .DX168B писал(а):И ,как ни странно, такие мысли бывают полезными для саморазвития*.
И все таки мне интересно было бы поболтать о процессоростроительстве ..
Одна из Ваших мыслей по сути подходит почти вплотную к уже существующей идее управляющего ядра без а.л.у. - только "руление" шинами и передача заданий а.л.у.( их может быть и несколько ) и в др. обрабатывющие устройства.
Кроме того на nedopc.org/forum уже обсуждался принцип непосредственного изполнения объектов - когда у данных есть тег, описывающий тип и возможные процедуры/операции над таковыми данными.
Управляющему ядру остаётся лишь направить таковые данные в соответствующее обрабатывающее устройство - как частный случай - арифметические&логические данные направить в а.л.у.
Как говорится "идея витает в воздухе" - осталось попробовать ..

Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 21:43:03
Сразу возникает вопрос "Зачем?" Обычно ответом является баланс между "Быстро", "Универсально", "Дёшево". Именно баланс, так как программы с различным назначением на разных процессорах будут выполняться с разной эффективностью. Не говоря уже о том, что одну и ту же программу можно для одного и того же процессора можно написать совершенно различными в плане оптимальности (память программ, память переменных, быстродействие, предсказуемость времени выполнения) способами. При наличии конвейера программ эти способы порой становятся совершенно неочевидными.
Я думаю, что концептуальная красота кодировки команд, которую преследует автор топика, — это самое последнее, о чём надо задумываться при создании микропроцессора. Нечто близкое к этому понятию родится автоматически, если разработчик будет преследовать цель создать микропроцессор (микроконтроллер) с наиболее оптимальным ядром и/или с возможностью дальнейшего масштабирования набора инструкций.
Добавлено after 9 minutes 5 seconds:
Re: Микропроцессоры: Попытки разработки собственной архитектуры
Я думаю, что концептуальная красота кодировки команд, которую преследует автор топика, — это самое последнее, о чём надо задумываться при создании микропроцессора. Нечто близкое к этому понятию родится автоматически, если разработчик будет преследовать цель создать микропроцессор (микроконтроллер) с наиболее оптимальным ядром и/или с возможностью дальнейшего масштабирования набора инструкций.
Я думаю, для самообучения в первую очередь было бы полезно разобраться в уже имеющихся процессорах, попытаться понять или поднять историю вопроса, почему в том или ином моменте было выбрано именно такое решение, а не какое-то другое, и к каким неудачным последствиям это решение привело в последующем.petrenko писал(а):Именно для самообучения - наилучшим образом !
Добавлено after 9 minutes 5 seconds:
Re: Микропроцессоры: Попытки разработки собственной архитектуры
Ну, например, разница между Z80 и семейством микроконтроллеров AVR, что мне доводилось программировать, бросается в глаза сразу: в первом шина для данных и команд одна, во втором — их две, по одной на каждую. В Z80 и AVR внешние устройства адресуются через специально адресное пространство — порты ввода-вывода, а в STM32 микроконтроллерах адресное пространство для устройств, оперативной памяти и ПЗУ едино. Я ещё далеко дилетант в подобных вопросах, хоть и занимаюсь периодически программированием на ассемблере, но мне кажется, что есть и другие походы к вопросу.Paguo-86PK писал(а):А насчёт архитектуры... Если я не очень ошибаюсь, именно архитектурой ВМ80 описывалось, что все арифметико-логические действия производятся с аккумулятором; что имеется поддержка до 256 УВВ; что максимально адресуемое пространство - 64кб; что поддерживается прямая и косвенная адресация
Последний раз редактировалось B@R5uk Чт янв 12, 2017 21:55:05, всего редактировалось 1 раз.
Микропроцессоры: "размышления на унитазе" об улучшайзинге
Чт янв 12, 2017 21:49:18
*_Ну это вовсе не резкая, а весьма даже мягкая критикаPaguo-86PK писал(а):.. достаточно резкую* критику..
..
.. разве я не достаточно уделил внимания этим деталям** ? ..
**_Вот деталям то как раз более, чем предостаточно, внимания. Жаль, что основной смысл критики Вы ещё не поняли. Не отчаивайтесь - перечитайте сообщение, ну .. и .. нарисуйте , что ли .. блок-схему .. пожалуйста .. , а то обсуждать ну совсем нечего по существу названия темы.
Воистину так !думаю, что концептуальная красота кодировки команд, .. - это самое последнее, о чём надо задумываться
Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 21:49:52
В IBM-подобных системах обнулением памяти занимается биос на этапе проверки работоспособности памяти. При включении память забита мусором. Единственный способ "сбросить" динамическое ОЗУ — записать туда конкретное значение. Этим значением может быть команда NOP или любая другая по вашему желанию.Paguo-86PK писал(а):Так, например, меня возмутило, что в i8086 коду 00 соответствует операция ADD, что сбивает с толку, если память обнулена.
В микроконтроллерах, память ограничена и выполняется на триггерах, поэтому имеет возможность быть сброшеной в ноль по сигналу линии сброса. Она не требует обновления и может сохранять свои значения, даже если ядро простаивает (пока питание включено, разумеется).
Re: Микропроцессоры: "размышления на унитазе" об улучшайзинг
Чт янв 12, 2017 21:57:11
petrenko писал(а):Кроме того на nedopc.org/forum уже обсуждался принцип непосредственного изполнения объектов - когда у данных есть тег, описывающий тип и возможные процедуры/операции над таковыми данными.
Управляющему ядру остаётся лишь направить таковые данные в соответствующее обрабатывающее устройство - как частный случай - арифметические&логические данные направить в а.л.у.
Ну, в принципе, это можно назвать дальнейшим развитием моих мыслей. Типа, собрать инструкции в блоки и пометить блок тегом.
После того, как блок загрузится в конвейер, передать его соответствующему узлу на исполнение. Тег может представлять собой номер узла, которому этот блок предназначен. А если этот блок состоит из независимых друг от друга операций, то их можно выполнить параллельно. Короче, тут можно развивать, развивать и получить "Эльбрус".
Микропроцессоры: Попытки разработки собственной архитектуры
Чт янв 12, 2017 21:59:50
Интуитивно ясная расстановка команд
На уровне машинного кода система команд устроена гораздо проще, чем может показаться на первый взгляд.
Так, инструкции с симметричными тетрадами (нибблами) с кодами 11/22/33/44/55/66/77 являются префиксами подмены действующего аккумулятора или указателя.
Операции АЛУ также занимают интуитивно понятные позиции: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR).
Частые команды имеют краткий код
Оглядываясь на x86 не я первый не могу сдержать критику: Таблица команд давно стала мусоркой. Все MMX/SSE команды свалились под префикс 0F; Сегментные префиксы, благополучно отжившие свой век, зря пожирают пространство машинного кода. Многие инструкционные комбинации как были под статусом "зарезервировано", так и остались.
Тем самым, в своей концепции процессора я и это учитывал. Специально нет никаких всяких префиксов, которые пришлось бы потом выкидывать. Нет специальных инструкций доступа к портам, запрета/разрешения прерываний, доступа к служебным регистрам.
В управляющей программе, чтобы записать байт в системный регистр, нужно нагородить друг на друга три инструкции, общей длиною в 6 байт. Это - не особенная привелегированная команда. А необычное сочетание из трёх самых обычных команд.
Дешифратор команд
На выполнение одной команды может затрачиваться от четырёх до нескольких десятков тактов.
Если же инструкции "упаковываются" в специально отведённый буфер статической памяти, из которой их выборка может занимать уже от 1 такта на команду. Всего можно иметь заготовку до 10 таких макросов, каждый длиною до 7 команд.
Обработка прерываний
Говоря простым языком, внутри всего системного кода высшего уровня привелегий прерывания запрещены. При исполнении кода прикладных задач прерывания всегда разрешены.
Чтобы проверить наличие внешнего аппаратного прерывания, системному коду достаточно передать управление любому коду прикладного уровня. В таком случае выполнение приложение приостановится, а системный код получит индекс ситуации от периферии.
Переключение между задачами
В состав служебных регистров входит счётчик тактов с обратным отсчётом. В привелегированном режиме системного кода его счёт заморожен и перед передачей управления конкретному приложению ядро должно предустановить этот счётчик согласно приоритету данной задачи. Внутри исполняемой прикладной задаче счётчик работает на декремент до обнуления. Его обнуление приостанавливает выполнение текущего приложения и управление возвращается ядру системы.
Как указано выше, приложение приостанавливается и в случаях сбоя страниц памяти, встречи зарезервированной инструкции, сбоя стека и т.д.
Сбой стека (в проработке)
Указатель стека всегда обязан быть выравненным по модулю 2.
Команды вызова подпрограммы (CALL) и возврата (RET) устанавливают младший бит SP в 1 и нарушают тем самым это выравнивание. В этом случае не могут работать и PUSH/POP команды, прерывая выполнение приложения с соответствующим индексом ошибки для ядра. Это помогает бороться с "кривым" кодом в критических местах. Программист должен ответственее заниматься с вопросом аккуратности своей программы.
Так, например, операция доступа к несуществующей странице памяти не вызовет ошибку или исключение на первом шаге. Просто, младший бит указателя стека собъёт выравнивание. Нормальный алгоритм должен регулярно проверять этот статус стека, аналогично GetLastError в Win-API после выполнения нестабильных процедур. Если код программы прошёл мимо ситуации, то сбитый бит указателя стека не даст выполнится командам CALL/RET/PUSH/POP и произойдёт явная ошибка с возвратом управления ядру.
P.S.: Разные ссылочки:
BMOW
Процессор и ПК своими руками: проект BMOW 1
Homebrew Computer
Учебные процессоры (00 - HLT)
На уровне машинного кода система команд устроена гораздо проще, чем может показаться на первый взгляд.
Так, инструкции с симметричными тетрадами (нибблами) с кодами 11/22/33/44/55/66/77 являются префиксами подмены действующего аккумулятора или указателя.
Операции АЛУ также занимают интуитивно понятные позиции: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR).
Частые команды имеют краткий код
Оглядываясь на x86 не я первый не могу сдержать критику: Таблица команд давно стала мусоркой. Все MMX/SSE команды свалились под префикс 0F; Сегментные префиксы, благополучно отжившие свой век, зря пожирают пространство машинного кода. Многие инструкционные комбинации как были под статусом "зарезервировано", так и остались.
Тем самым, в своей концепции процессора я и это учитывал. Специально нет никаких всяких префиксов, которые пришлось бы потом выкидывать. Нет специальных инструкций доступа к портам, запрета/разрешения прерываний, доступа к служебным регистрам.
В управляющей программе, чтобы записать байт в системный регистр, нужно нагородить друг на друга три инструкции, общей длиною в 6 байт. Это - не особенная привелегированная команда. А необычное сочетание из трёх самых обычных команд.
Дешифратор команд
На выполнение одной команды может затрачиваться от четырёх до нескольких десятков тактов.
Если же инструкции "упаковываются" в специально отведённый буфер статической памяти, из которой их выборка может занимать уже от 1 такта на команду. Всего можно иметь заготовку до 10 таких макросов, каждый длиною до 7 команд.
Обработка прерываний
Говоря простым языком, внутри всего системного кода высшего уровня привелегий прерывания запрещены. При исполнении кода прикладных задач прерывания всегда разрешены.
Чтобы проверить наличие внешнего аппаратного прерывания, системному коду достаточно передать управление любому коду прикладного уровня. В таком случае выполнение приложение приостановится, а системный код получит индекс ситуации от периферии.
Переключение между задачами
В состав служебных регистров входит счётчик тактов с обратным отсчётом. В привелегированном режиме системного кода его счёт заморожен и перед передачей управления конкретному приложению ядро должно предустановить этот счётчик согласно приоритету данной задачи. Внутри исполняемой прикладной задаче счётчик работает на декремент до обнуления. Его обнуление приостанавливает выполнение текущего приложения и управление возвращается ядру системы.
Как указано выше, приложение приостанавливается и в случаях сбоя страниц памяти, встречи зарезервированной инструкции, сбоя стека и т.д.
Сбой стека (в проработке)
Указатель стека всегда обязан быть выравненным по модулю 2.
Команды вызова подпрограммы (CALL) и возврата (RET) устанавливают младший бит SP в 1 и нарушают тем самым это выравнивание. В этом случае не могут работать и PUSH/POP команды, прерывая выполнение приложения с соответствующим индексом ошибки для ядра. Это помогает бороться с "кривым" кодом в критических местах. Программист должен ответственее заниматься с вопросом аккуратности своей программы.
Так, например, операция доступа к несуществующей странице памяти не вызовет ошибку или исключение на первом шаге. Просто, младший бит указателя стека собъёт выравнивание. Нормальный алгоритм должен регулярно проверять этот статус стека, аналогично GetLastError в Win-API после выполнения нестабильных процедур. Если код программы прошёл мимо ситуации, то сбитый бит указателя стека не даст выполнится командам CALL/RET/PUSH/POP и произойдёт явная ошибка с возвратом управления ядру.
P.S.: Разные ссылочки:
BMOW
Процессор и ПК своими руками: проект BMOW 1
Homebrew Computer
Учебные процессоры (00 - HLT)
Последний раз редактировалось Paguo-86PK Чт янв 12, 2017 22:26:08, всего редактировалось 1 раз.
Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 22:22:24
Расстановку команд логичнее производить на этапе разводки ядра процессора, таким образом, чтобы эта разводка и схемотехника были наиболее просты. Снижает цену процессора. Компилятору будет всё равно, какая кодировка у какой команды.Paguo-86PK писал(а):Операции АЛУ также занимают интуитивно понятные позиции: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR).
Микропроцессоры: Попытки разработки собственной архитектуры
Чт янв 12, 2017 22:41:01
Вот тут то я категорически не согласен.B@R5uk писал(а):Расстановку команд логичнее производить на этапе разводки ядра процессора, таким образом, чтобы эта разводка и схемотехника были наиболее просты. Снижает цену процессора. Компилятору будет всё равно, какая кодировка у какой команды.Paguo-86PK писал(а):Операции АЛУ также занимают интуитивно понятные позиции: A(Add)/B(suB)/C(Conjunction-AND)/D(Disjunction-OR)/E(Exclusive OR).
При разводке ядра i8086 может это было и актуально. Но, с приходом i386, i486, Pentium и т.д. расстановка команд стала не так актуальна и 00-ADD стало выглядить по-идиотски

Пытаясь глядеть чуточку вдаль, расстановку команд я делал исходя из эстетического и интуитивного визуального охвата таблицы взглядом, а не прикидывая на миллиметровке расстояния проводков.
Согласитесь, что и жёсткий табличный синтаксис ФОРТРАНа, очень актуальный на заре ЯВУ, очень потом непрягал всех в 80-90-х. В конце-концов, в новых стандартах версий языка синтаксис сделали более свободным.
Тем самым, я принципиально не опираюсь на технические издержки реализации ядра при разработке таблицы команд.
Кишки ядра процессора не должны вылазить грыжей системы команд.
(кстати, NOP у меня раньше был в центре - код 80h (эстетически). но в ассемблере, дизассемблере и самом дешифраторе было много напряга из-за этого. я его сместил до FEh и доволен. вникните в идеалогию процессора и поймёте, почему)
(к тому же процессор - не для индусов: по-идее, школьник, уже владеющей таблицей умножения, может научиться голыми руками бить байт-код под этот процессор, как некогда бил и я 25 лет назад в дампах РАДИО-86РК)
P.S.: Всё таки XXI век и в FPGA-реализации процессора на таблицу команд расположение вентилей не должно оказывать никакого влияния.
(пап, а почему в IA-64 00=ADD? сынок, в Интел тогда был напряг и жало паяльника достало от сумматора до первой ножки дешифратора
)
Re: Микропроцессоры: Попытки разработки собственной архитект
Чт янв 12, 2017 23:36:59
ТС, а ваш процессор - это виртуально-программный продукт, или же реальное железное воплощение на транзисторах\ТТЛ логике?
Микропроцессоры: Попытки разработки собственной архитектуры
Пт янв 13, 2017 00:26:17
Вoт это вопрос по существуLastHopeMan писал(а):ТС, а ваш процессор - это виртуально-программный продукт, или же реальное железное воплощение на транзисторах\ТТЛ логике?

Этот процессор - наверное тридцатый по счёту, который мне удалось оживить эмуляцией.
До этого, ещё с 17 лет, пытался разработать идеальный процессор без пережитков прошлых эпох. Но, дальше набросков дела не доходило, так как приступая к эмуляции натыкался на ряд концептуальных проблем (загрузка в стек на деле не такая, например, как намечалась. и т.д.)
Можно сказать, это - первый практический шаг, где и эмулятор работает, и дизассемблер имеется, и ассемблер сносно работает, и несколько задач одновременно выполняется в среде с командной строкой.
Правда, есть букет недочётов, с которыми нужно долго и нудно справляться. Но, практически, то, что 20 лет назад я набросал в DOS 3.11 на "Поиске", мне наконец-то удалось "оживить".
Думаю, в одиночку впихивать всё это в ПЛИС буду годами. Так как и в Chrome консоли с пошаговой отладкой скрипта чудовищно сложно отлавливать все глючные ситуации.
По моим скромным и крайне грубым оценкам реализация процессора паяльником потребует около 20 тысяч транзисторов, что слишком избыточно.
Но, здесь имеются могучие перспективы. Например, подключая к его шине какое-либо устройство, непосредственно а самой системе команд появляется префикс для работы с этим устройством. Так, код E0-E9 не имеет никаких инструкций и команды с этим кодом нельзя использовать, так как приложение свалится исключением в ядро. Ядро же само может подтянуть и программно интерпретировать эти команды. Но, если физически к процессору подключено какое-то устройство и за ним закреплён один из тех кодов, то это устройство станет продолжением дешифратора процессора и обработает нужную операцию само. К тому же процессор должен иметь непосредственные вывода для доступа к регистровому файлу. Что позволило бы наращивать систему команд аппаратно. Будь то инструкции FPU/MMX/SSE или какие-то другие.
P.S.: Планы, конечно, амбициозно грандиозные.
Как видно из официальной странички, x80 - желаемая линейка, подобно x86, где совместимость должна сохраняться между друг другом, и разрядность от 8 до 16- и 32-бит намечается в перспективе.
Причём, какрас-таки совместимость в обе стороны: Если нужно выполнить программу "свежего" процессора на "старом", где нет каких-то инструкций, их можно эмулировать ядром программно или электрически подключив к процессору нужное устройство как приставку м нарастить дешифратор ядра. О чём я мечтал 20 лет назад

Re: Микропроцессоры: Попытки разработки собственной архитект
Пт янв 13, 2017 01:12:07
Пускать устройства за дешифратором - это здравая идея, как идея. Я именно так планирую устраивать свою самоделку. Но если присмотреться, то типовая схема интеловских ПК как раз и являлась этим воплощением. Общая шина, процессор командует устройствами на ней. А вы похоже хотите, чтобы внутри процессора тоже сложилась подобная система, если я правильно понял. Это хорошая мысль, если процессор является сборным с "модулями", которые можно было бы подключать. Но в наше время УЖЕ не практично. Линии длиннее, размеры больше. Поэтому перспектив у данного подхода нет - вся высокочастотность в укорочении линий внутри процессора. Что же касается опкодов и анекдота про сумматор, то на самом деле все именно так. Когда я приступил к написанию хоть какой-то схемы для подобной вещицы, то в первый же день стало очевидно: ради простоты конструкции я готов пожертвовать 90% функциональности и быстродействия. Будь у меня завод под рукой - все равно бы сделал также. Дешифратор - это чертовски слабое место на мой взгляд, при сложной его архитектуре (команды вперемешку различного назначения) дешифрация некоторых команд может занимать ощутимое время, либо ощутимое количество транзисторов. Это все чертовски не окупается. Пока это все виртуально, то можно оптимизировать и структурировать. Как только переходим к практике - увы...
Микропроцессоры: Попытки разработки собственной архитектуры
Пт янв 13, 2017 13:11:31
Когда в детстве читал отцовские справочники с описанием устройств ЭВМ, иногда мечтал быть инженером и участвовать в разработках машин, подобных Cray и CYBER…LastHopeMan писал(а):Пускать устройства за дешифратором - это здравая идея, как идея. Я именно так планирую устраивать свою самоделку. Но если присмотреться, то типовая схема интеловских ПК как раз и являлась этим воплощением. Общая шина, процессор командует устройствами на ней. А вы похоже хотите, чтобы внутри процессора тоже сложилась подобная система, если я правильно понял. Это хорошая мысль, если процессор является сборным с "модулями", которые можно было бы подключать. Но в наше время УЖЕ не практично. Линии длиннее, размеры больше. Поэтому перспектив у данного подхода нет - вся высокочастотность в укорочении линий внутри процессора. Что же касается опкодов и анекдота про сумматор, то на самом деле все именно так. Когда я приступил к написанию хоть какой-то схемы для подобной вещицы, то в первый же день стало очевидно: ради простоты конструкции я готов пожертвовать 90% функциональности и быстродействия. Будь у меня завод под рукой - все равно бы сделал также. Дешифратор - это чертовски слабое место на мой взгляд, при сложной его архитектуре (команды вперемешку различного назначения) дешифрация некоторых команд может занимать ощутимое время, либо ощутимое количество транзисторов. Это все чертовски не окупается. Пока это все виртуально, то можно оптимизировать и структурировать. Как только переходим к практике - увы...
На фотографиях видно, как много там было кабелей. Что, тем не менее, не мешало нормальной работе. Вот вами выше сказано, что в i8086 команда ADD получила код 00 в частности по прихоти длины проволочек дешифратора на кристалле.
Сравните фотографии кристаллов процессоров одной линейки. Видно, что на первом - сплошной бардак из спаек проволок, тогда как дальше структура становится более чёткой и красивой. И нет никакого оправдания причудам оптимизации дешифратора команд с уродованием таблицы системы команд первого i8086.
Как-то в Visual Basic мною был придуман оригинальный элемент управления. И вместо того, чтобы получить хоть какие-то авторские права на него, я занялся оптимизацией его прорисовки. Один из друзей как-то спросил, мол зачем оптимизировать под платформу Windows, когда это сделают другие под свою платформу? Главное - получить права авторства. Но нет же, я как программист, а не предприниматель, достал Visual C++ 6 и продолжал оптимизировать прорисовку уже на ассемблере до уровня MMX…
А теперь, на любых Андроидах встречаются элементы настройки, точь-в-точь сходные с тем, что я в свои годы, дурак, тупо оптимизировал.
А вы настаиваете, что на практике я увижу, что коды некоторых инструкций разумнее было изменить, чем паять проволоку на 10 см длиннее. Согласен, так как сталкивался с подобными ситуациями. Отец и вовсе спаял клавиатуру Радио-86РК паутиной проволочек и я ужасался путаннице. Пока не научился разбираться в схемах и не понял, что оригинальная клавиатура РК хоть схематически запутана из-за расскладки, но программно - не требует таблиц и прозрачна для кода. В отличии от клавиатуры ZX-Spectrum - сверх-простой схематически, но требующей таблицы раскладки.
P.S.: На счёт внедрения внешних устройств напрямую в систему команд с доступом к регистровому фрейму текущей задачи из-вне скажу вот что. Сейчас существует уйма сверхскоростных протоколов, типа I²C, 1-wire, USB 3.0 и т.д. Нет никаких запретов об организации подобия сетевого обмена между внешним устройством и ядром самого собственного процессора. Тем самым, потребуется всего несколько выводов скоростной последовательной линии, чтобы внешняя "карточка" внедрилась в сам дешифратор команд процессора и обрабатывала исключительно свои инструкции, как некогда было с i8087.
- Вложения
-
- super.15.jpeg
- CYBER 205 фирмы Control Data Corporation, конкурирующий с Cray-1. Изображенное здесь устройство проходит окончательные испытания на заводе фирмы в Арден-Хиллсе (шт. Миннесота). Стоимость CYBER 205, так же как и Cray-1, составляет от 10 до 15 млн. долл. в зависимости от поставляемого объёма памяти и другого дополнительного оборудования. Первый CYBER 205 был поставлен в Метеорологическую службу Великобритании в 1981 г. Использование численных методов в предсказании погоды вызвало необходимость развития суперкомпьютеров, которое началось с создания MANIAC (Mathematical Analyzer, Numerical Integrator and Computer), разработанного в конце 1940 г. под руководством Джона фон Неймана. Компьютер CYBER 205 представляет собой усовершенствованный вариант машины STAR 100 фирмы Control Data и имеет длительность цикла 20 нс. Поскольку Cray-1 - очень компактное устройство, сигналы в нем могут передаваться от одной точки к другой со скоростью, обеспечиваемой медным проводником, т. е. примерно 0,3 скорости света. Чтобы уменьшить время прохождения сигналов в CYBER 205, который имеет значительно большие размеры, разработчики предусмотрели соединение нескольких тысяч схемных плат коаксиальными кабелями, по которым сигналы распространяются со скоростью, примерно равной 0,9 скорости света.
- (179.54 KiB) Скачиваний: 479
-
- super.13.jpeg
- Компьютер CRAY-1 (слева) фирмы Cray Research, Inc.- это одна из двух поступающих сегодня в продажу машин с максимальной производительностью не менее 100 млн. арифметических операций в секунду. На фотографии представлена модель, недавно установленная в Ames Research Center, где до этого работал ILLIAC IV. БОльшая из двух стоек, изображенных на переднем плане, - это основная часть компьютера, в которой расположены центральный процессор и центральная память. Меньшая стойка - подсистема ввода/вывода, состоящая из трех малых быстродействующих машин и дополнительных устройств памяти. В выступающей части основания большой стойки находится блок питания. На фотографии справа показаны задние панели стоек, где видно переплетение проводников, которые соединяют более 1600 схемных плат центрального процессора. Проводники, общее число которых около 300 тысяч, подобраны по длине таким образом, чтобы сигналы проходили между любыми двумя точками за требуемый интервал времени с разбросом не более 1 нс. Рабочий цикл машины равен 12,5 нс.
- (175.96 KiB) Скачиваний: 474
Re: Микропроцессоры: Попытки разработки собственной архитект
Пт янв 13, 2017 18:27:08
Как-то так:


Можно добавить еще мультиплексоры на регистр SR, указатель стека и прочее.
Замысел во второй картинке заключается в том, что операнды узел забирает сам, покрутив счетчик PC.
Таим образом можно создавать инструкции с большим числом операндов. В качестве первого операнда можно указать количество рабочих операндов, чтобы узел, загрузив его, мог сориентироваться, сколько операндов можно забрать из памяти до появления следующей инструкции. А транслятор ассемблера можно реализовать так, чтобы транслятор сам вставлял количество операндов.
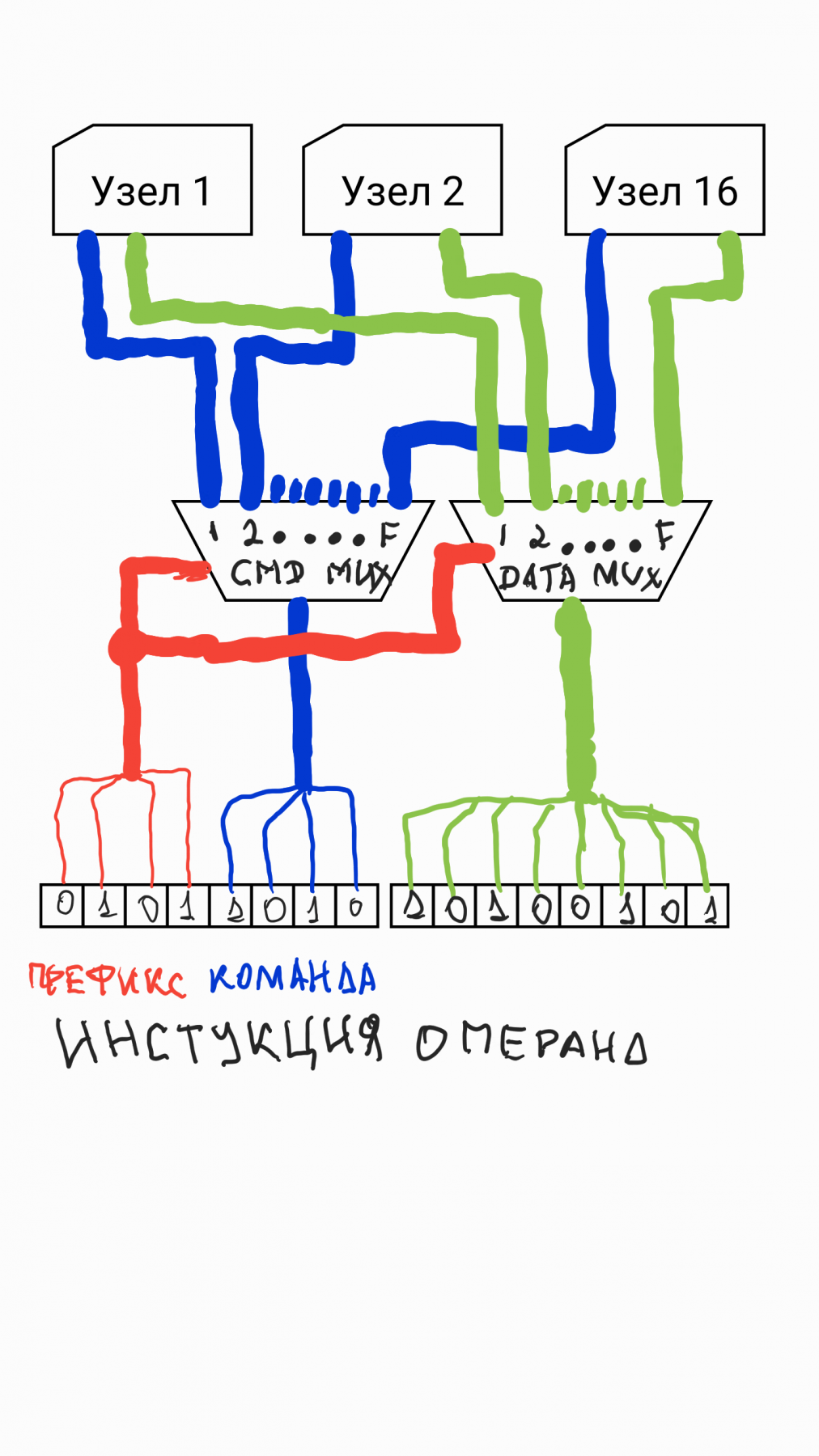
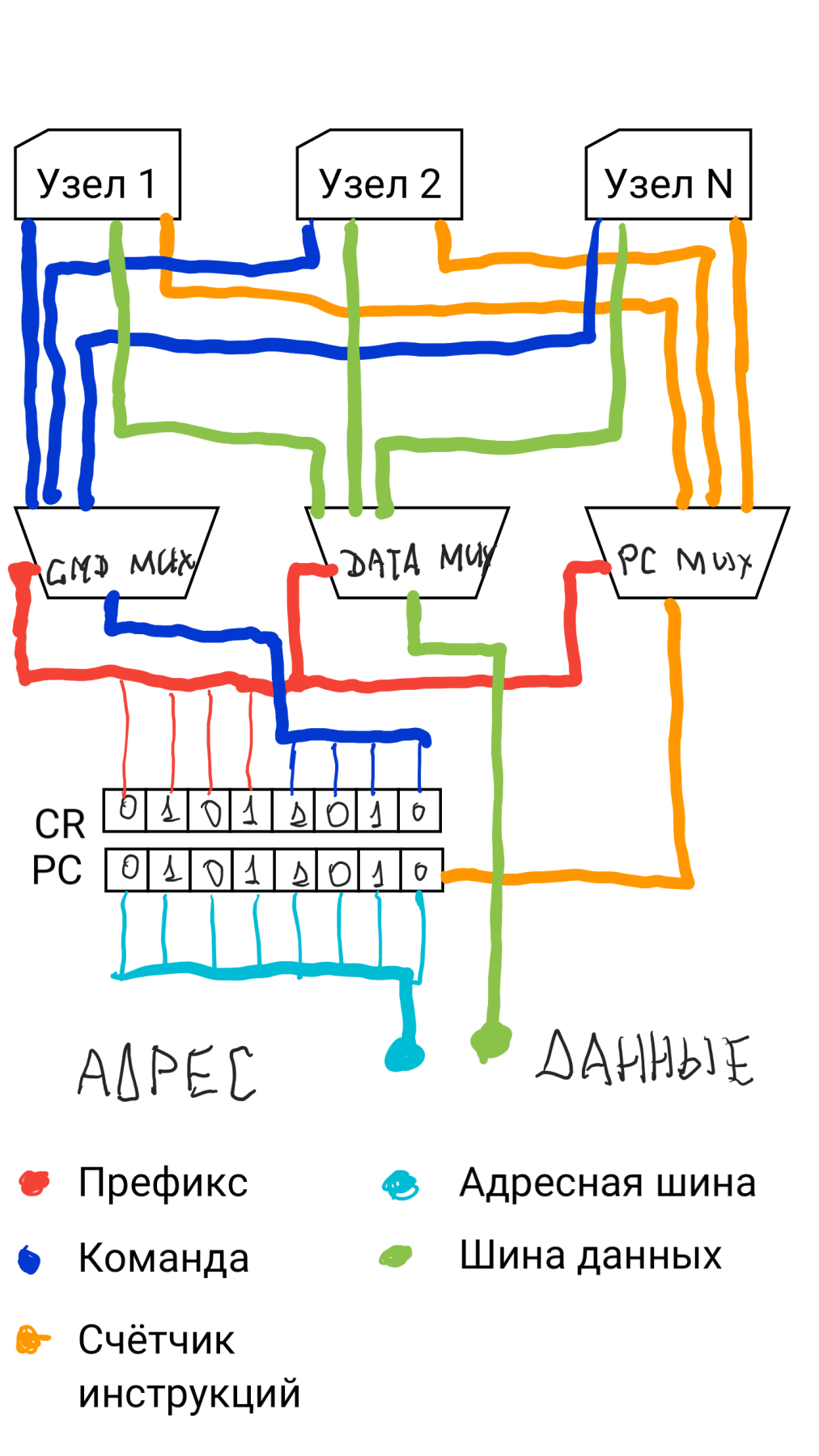
Можно добавить еще мультиплексоры на регистр SR, указатель стека и прочее.
Замысел во второй картинке заключается в том, что операнды узел забирает сам, покрутив счетчик PC.
Таим образом можно создавать инструкции с большим числом операндов. В качестве первого операнда можно указать количество рабочих операндов, чтобы узел, загрузив его, мог сориентироваться, сколько операндов можно забрать из памяти до появления следующей инструкции. А транслятор ассемблера можно реализовать так, чтобы транслятор сам вставлял количество операндов.
Микропроцессоры: Попытки разработки собственной архитектуры
Пт янв 13, 2017 19:03:47
Вaш процессор напоминает мой, который многие критикуют. Суть которого в том, что АЛУ в нём отсутствует, но он просто работает как маршрутизатор потоков данных между всеми внешними устройствами, как умный ПДП. Подключив к нему внешние FPU/ALU - получаем полноценное процессорное устройство.DX168B писал(а):Можно добавить еще мультиплексоры на регистр SR, указатель стека и прочее.
Замысел во второй картинке заключается в том, что операнды узел забирает сам, покрутив счетчик PC.
Таим образом можно создавать инструкции с большим числом операндов. В качестве первого операнда можно указать количество рабочих операндов, чтобы узел, загрузив его, мог сориентироваться, сколько операндов можно забрать из памяти до появления следующей инструкции. А транслятор ассемблера можно реализовать так, чтобы транслятор сам вставлял количество операндов.
P.S.: В архиве - заброшенный набросок процессора, который не имеет системы команд. Он сразу читает ascii-листинг с синтаксисом, сходным с Си.
Некогда я его отлаживал и пытался докатить его до рабочего состояния.
В этом процессоре, например, 2x += 3y означает, что нужно прочитать 3 байта по адресу y и суммировать их к 2 байтам по адресу x. Причём, x и y - не переменные, а прямое указание адреса (код буквы x/y - и есть адрес). Если написать 1keybd = 1xyz, то keybd и xyz уже является 32-битными векторами на ячейки. Тем самым, на выполнение одной операции мужет уходить до 100 тактов. Эдакий, аппаратный Бейсик.…
- Вложения
-
- cpu.zip
- Icarus Verilog Project
- (4.73 KiB) Скачиваний: 218