Умножение и возведение в квадрат без аппаратной поддержки
Пт апр 08, 2022 18:34:01
Пишу на асме под ATtiny2313A.
Затребовалось мне посчитать сумму квадратов трёхбайтных величин. Я, в принципе, знаю один способ умножения столбиком. В нём произведение строится в цикле по битам одно сомножителя прямо на месте другого сомножителя (с добавлением дополнительных байт для хранения результата, разумеется). Соответствующая процедура очень компактна по коду и использует минимально возможное число регистров процессора (1 на счётчик, n на один множитель и n*m на результат и другой множитель, размер которого m байт). Но она жутко медленная, а мне нужно считать квадраты в прерывании быстро.
Я знаю другой способ, с использованием таблиц квадратов. Кто не знаком с ним, вот эту статью можно взять за отправную точку. Единственный минус подхода в статье заключается в том, что там используют сумму сомножителей, которая на один бит выходит за пределы размера сомножителей. Использование схемы ab = (a^2 + b^2 - (a - b)^2) / 2 более рационально в плане памяти, на мой взгляд. Особенно, если учесть, что таблица квадратов байта занимает в памяти 512 байт, что уже составляет 25% от всего ПЗУ моего МК.
Для построения программы составил себе шпаргалку:
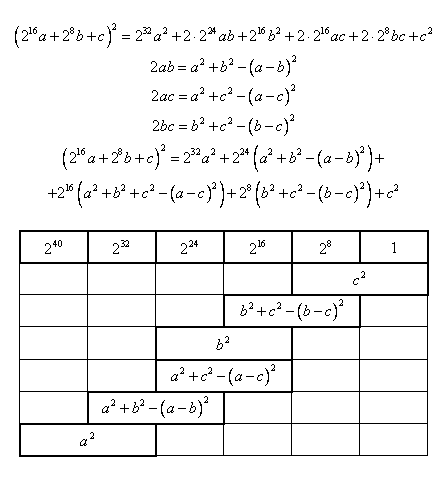
Теперь вот думаю, как бы это по-лучше всё складывать. Квадраты будут суммироваться в кумулятивную сумму, которую логично хранить в оперативке. Так как обращение к ней медленнее, чем к регистрам, то логично формировать каждый байт-разряд суммы залпом, один раз читая его в начале и один раз записывая его в конце. Чтение таблицы квадратов из ПЗУ тоже не быстрая операция, поэтому логично читать каждый квадрат один раз и хранить результат в регистре, пока в нём есть потребность. Чтобы не таскать перенос от сложения по всей сумме от текущего разряда до самого старшего, логично собирать все переносы в отдельный регистр и добавлять к следующему разряду суммы, только когда приступим к его формированию. В итоге требуется очень много регистров МК, чтобы процедура работала шустро. Возможно, где-то быстродействием стоит пожертвовать, чтобы сократить расход регистров, они и в других частях программы используются.
Кто-нибудь делал что-нибудь подобное? Какие могут быть советы/рекомендации?
Добавлено after 2 hours 5 minutes 53 seconds:
Как-то так выглядит умножение двух байт:
Для работы процедуры в памяти должна быть размещена вот такая таблица (фактически две таблицы: младший байтов квадратов и старших):
При этом важно, чтобы адрес таблицы в памяти был "круглым": заканчивался на 0x00 или 0x80.
Затребовалось мне посчитать сумму квадратов трёхбайтных величин. Я, в принципе, знаю один способ умножения столбиком. В нём произведение строится в цикле по битам одно сомножителя прямо на месте другого сомножителя (с добавлением дополнительных байт для хранения результата, разумеется). Соответствующая процедура очень компактна по коду и использует минимально возможное число регистров процессора (1 на счётчик, n на один множитель и n*m на результат и другой множитель, размер которого m байт). Но она жутко медленная, а мне нужно считать квадраты в прерывании быстро.
Я знаю другой способ, с использованием таблиц квадратов. Кто не знаком с ним, вот эту статью можно взять за отправную точку. Единственный минус подхода в статье заключается в том, что там используют сумму сомножителей, которая на один бит выходит за пределы размера сомножителей. Использование схемы ab = (a^2 + b^2 - (a - b)^2) / 2 более рационально в плане памяти, на мой взгляд. Особенно, если учесть, что таблица квадратов байта занимает в памяти 512 байт, что уже составляет 25% от всего ПЗУ моего МК.
Для построения программы составил себе шпаргалку:
Теперь вот думаю, как бы это по-лучше всё складывать. Квадраты будут суммироваться в кумулятивную сумму, которую логично хранить в оперативке. Так как обращение к ней медленнее, чем к регистрам, то логично формировать каждый байт-разряд суммы залпом, один раз читая его в начале и один раз записывая его в конце. Чтение таблицы квадратов из ПЗУ тоже не быстрая операция, поэтому логично читать каждый квадрат один раз и хранить результат в регистре, пока в нём есть потребность. Чтобы не таскать перенос от сложения по всей сумме от текущего разряда до самого старшего, логично собирать все переносы в отдельный регистр и добавлять к следующему разряду суммы, только когда приступим к его формированию. В итоге требуется очень много регистров МК, чтобы процедура работала шустро. Возможно, где-то быстродействием стоит пожертвовать, чтобы сократить расход регистров, они и в других частях программы используются.
Кто-нибудь делал что-нибудь подобное? Какие могут быть советы/рекомендации?
Добавлено after 2 hours 5 minutes 53 seconds:
Как-то так выглядит умножение двух байт:
Спойлер
- Код:
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
; Процедура перемножает два байта табличным методом по формуле
; A * B = (A^2 + B^2 - (A - B)^2) / 2
; Используемые регистры:
; - r16 и r17 - исходные сомножители
; - r14 и r15 - возвращаемое произведение
; - r18 и r19 - вспомогательные регистры для промежуточных данных
; - Z - указатель для чтения таблицы квадратов в ПЗУ
; Размер процедуры 54 байта (27 инструкций)
; Время выполнения 45 тактов (включая rcall и ret)
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
mul_8x8: mov ZL, r16 ; Чтение из ПЗУ квадрата первого сомножителя
ldi ZH, HIGH(2*SquareTable1)
lpm r15, Z ; Старший байт квадрата
ldi ZH, HIGH(2*SquareTable0)
lpm r14, Z ; Младший байт квадрата
sub ZL, r17 ; Расчёт модуля разности сомножителей
brcc mul_8x8_
neg ZL ; Если разность отрицательна, то сменить знак
mul_8x8_: lpm r19, Z ; Чтение младшего байта квадрата разности
sub r14, r19 ; Вычитание его из результата
ldi ZH, HIGH(2*SquareTable1)
lpm r19, Z ; Чтение старшего байта квадрата разности
sbc r15, r19 ; Вычитание его из результата
sbc r18, r18 ; Сохранение заёма в старшем разряде
mov ZL, r17 ; Чтение квадрата второго сомножителя
ldi ZH, HIGH(2*SquareTable0)
lpm r19, Z ; Младший байт
add r14, r19 ; Сложение его с результатом
ldi ZH, HIGH(2*SquareTable1)
lpm r19, Z ; Старший байт
adc r15, r19 ; Сложение его с результатом
clr r19
adc r18, r19 ; Перенос в старший разряд
lsr r18 ; Деление результата на 2
ror r15
ror r14
ret
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
Для работы процедуры в памяти должна быть размещена вот такая таблица (фактически две таблицы: младший байтов квадратов и старших):
Спойлер
- Код:
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.org 0x0300
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
SquareTable0: .dw 0x0100, 0x0904, 0x1910, 0x3124, 0x5140, 0x7964, 0xA990, 0xE1C4
.dw 0x2100, 0x6944, 0xB990, 0x11E4, 0x7140, 0xD9A4, 0x4910, 0xC184
.dw 0x4100, 0xC984, 0x5910, 0xF1A4, 0x9140, 0x39E4, 0xE990, 0xA144
.dw 0x6100, 0x29C4, 0xF990, 0xD164, 0xB140, 0x9924, 0x8910, 0x8104
.dw 0x8100, 0x8904, 0x9910, 0xB124, 0xD140, 0xF964, 0x2990, 0x61C4
.dw 0xA100, 0xE944, 0x3990, 0x91E4, 0xF140, 0x59A4, 0xC910, 0x4184
.dw 0xC100, 0x4984, 0xD910, 0x71A4, 0x1140, 0xB9E4, 0x6990, 0x2144
.dw 0xE100, 0xA9C4, 0x7990, 0x5164, 0x3140, 0x1924, 0x0910, 0x0104
.dw 0x0100, 0x0904, 0x1910, 0x3124, 0x5140, 0x7964, 0xA990, 0xE1C4
.dw 0x2100, 0x6944, 0xB990, 0x11E4, 0x7140, 0xD9A4, 0x4910, 0xC184
.dw 0x4100, 0xC984, 0x5910, 0xF1A4, 0x9140, 0x39E4, 0xE990, 0xA144
.dw 0x6100, 0x29C4, 0xF990, 0xD164, 0xB140, 0x9924, 0x8910, 0x8104
.dw 0x8100, 0x8904, 0x9910, 0xB124, 0xD140, 0xF964, 0x2990, 0x61C4
.dw 0xA100, 0xE944, 0x3990, 0x91E4, 0xF140, 0x59A4, 0xC910, 0x4184
.dw 0xC100, 0x4984, 0xD910, 0x71A4, 0x1140, 0xB9E4, 0x6990, 0x2144
.dw 0xE100, 0xA9C4, 0x7990, 0x5164, 0x3140, 0x1924, 0x0910, 0x0104
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
SquareTable1: .dw 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000
.dw 0x0101, 0x0101, 0x0101, 0x0201, 0x0202, 0x0202, 0x0303, 0x0303
.dw 0x0404, 0x0404, 0x0505, 0x0505, 0x0606, 0x0706, 0x0707, 0x0808
.dw 0x0909, 0x0A09, 0x0A0A, 0x0B0B, 0x0C0C, 0x0D0D, 0x0E0E, 0x0F0F
.dw 0x1010, 0x1111, 0x1212, 0x1313, 0x1414, 0x1515, 0x1716, 0x1817
.dw 0x1919, 0x1A1A, 0x1C1B, 0x1D1C, 0x1E1E, 0x201F, 0x2121, 0x2322
.dw 0x2424, 0x2625, 0x2727, 0x2928, 0x2B2A, 0x2C2B, 0x2E2D, 0x302F
.dw 0x3131, 0x3332, 0x3534, 0x3736, 0x3938, 0x3B3A, 0x3D3C, 0x3F3E
.dw 0x4140, 0x4342, 0x4544, 0x4746, 0x4948, 0x4B4A, 0x4D4C, 0x4F4E
.dw 0x5251, 0x5453, 0x5655, 0x5957, 0x5B5A, 0x5D5C, 0x605F, 0x6261
.dw 0x6564, 0x6766, 0x6A69, 0x6C6B, 0x6F6E, 0x7270, 0x7473, 0x7776
.dw 0x7A79, 0x7D7B, 0x7F7E, 0x8281, 0x8584, 0x8887, 0x8B8A, 0x8E8D
.dw 0x9190, 0x9493, 0x9796, 0x9A99, 0x9D9C, 0xA09F, 0xA4A2, 0xA7A5
.dw 0xAAA9, 0xADAC, 0xB1AF, 0xB4B2, 0xB7B6, 0xBBB9, 0xBEBD, 0xC2C0
.dw 0xC5C4, 0xC9C7, 0xCCCB, 0xD0CE, 0xD4D2, 0xD7D5, 0xDBD9, 0xDFDD
.dw 0xE2E1, 0xE6E4, 0xEAE8, 0xEEEC, 0xF2F0, 0xF6F4, 0xFAF8, 0xFEFC
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
При этом важно, чтобы адрес таблицы в памяти был "круглым": заканчивался на 0x00 или 0x80.
- Вложения
-
- TribyteSquare.png
- (2.93 KiB) Скачиваний: 687
Re: Умножение и возведение в квадрат без аппаратной поддержк
Пт апр 08, 2022 20:21:38
Как-то так выглядит умножение двух байт
Жесть
Может, не стоит изобретать велосипед?
- Вложения
-
- Снимок экрана 2022-04-08 201901.png
- (62.99 KiB) Скачиваний: 652
Re: Умножение и возведение в квадрат без аппаратной поддержк
Пт апр 08, 2022 21:46:47
B@R5uk, полностью поддерживаю Gudd-Head.
стандартное "тупое" умножение двух 1-байтных чисел с помощью сдвигов и сложения занимает 41 цикл вместе с rcall и ret. и вообще не требует никаких таблиц.
вот выдержка из файла, идущего в комплекте AvrStudio4:
что на 4 цикла быстрее твоего изобретенного "велосипеда".
и в AVR нет тактов, есть только циклы.
стандартное "тупое" умножение двух 1-байтных чисел с помощью сдвигов и сложения занимает 41 цикл вместе с rcall и ret. и вообще не требует никаких таблиц.
вот выдержка из файла, идущего в комплекте AvrStudio4:
Спойлер
- Код:
;***************************************************************************
;*
;* "mpy8u" - 8x8 Bit Unsigned Multiplication
;*
;* This subroutine multiplies the two register variables mp8u and mc8u.
;* The result is placed in registers m8uH, m8uL
;*
;* Number of words :34 + return
;* Number of cycles :34 + return
;* Low registers used :None
;* High registers used :3 (mc8u,mp8u/m8uL,m8uH)
;*
;* Note: Result Low byte and the multiplier share the same register.
;* This causes the multiplier to be overwritten by the result.
;*
;***************************************************************************
;***** Subroutine Register Variables
.def mc8u =r16 ;multiplicand
.def mp8u =r17 ;multiplier
.def m8uL =r17 ;result Low byte
.def m8uH =r18 ;result High byte
;***** Code
mpy8u: clr m8uH ;clear result High byte
lsr mp8u ;shift multiplier
brcc noad80 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad80: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad81 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad81: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad82 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad82: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad83 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad83: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad84 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad84: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad85 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad85: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad86 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad86: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
brcc noad87 ;if carry set
add m8uH,mc8u ; add multiplicand to result High byte
noad87: ror m8uH ;shift right result High byte
ror m8uL ;rotate right result L byte and multiplier
ret
что на 4 цикла быстрее твоего изобретенного "велосипеда".
и в AVR нет тактов, есть только циклы.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 08:48:56
Я знаком с двухсотым доком (давно это было, правда). Спасибо, что напомнили.
Вот только мне надо умножать/возводить в квадрат трёхбайтные числа. Подход, используемый в этом доке, не очень рационален, на мой взгляд. Простейший случай с двумя байтами я привёл как пример того, что происходит в табличном методе. В плане производительности/расхода он не очень показательный.
Добавлено after 1 hour 8 minutes 33 seconds:
Вот показательный вариант, он уже для двухбайтной величины. Накатал по-быстрому, без оптимизации расхода регистров.
Код под катом в 2 раза быстрее и меньше по размеру 200-доковской процедуры, оптимизированной под скорость, и в 3 раза быстрее компактной процедуры с циклом. С трёхбайтной величиной выигрыш, мне думается, будет ещё больше.
Шпаргалка к процедуре:
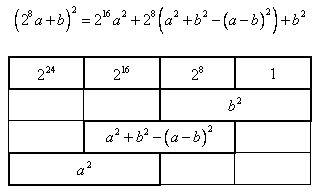
Спойлер
Starichok51, а можно код под кат спрятать?Вот только мне надо умножать/возводить в квадрат трёхбайтные числа. Подход, используемый в этом доке, не очень рационален, на мой взгляд. Простейший случай с двумя байтами я привёл как пример того, что происходит в табличном методе. В плане производительности/расхода он не очень показательный.
Добавлено after 1 hour 8 minutes 33 seconds:
Вот показательный вариант, он уже для двухбайтной величины. Накатал по-быстрому, без оптимизации расхода регистров.
Спойлер
- Код:
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
; Процедура возводит в квадрат двухбайтную величину
; и добавляет результат к кумулятивной сумме
; Используемые регистры:
; - r16 и r17 - исходная величина
; - r10 - r14 - кумулятивная сумма (5 байт)
; - r18 - r24 - вспомогательные регистры для промежуточных данных (7 штук)
; - zero - глобальный (для всей программы) регистр с нулевым значением
; Размер процедуры 64 байта (32 инструкции)
; Время выполнения 50 тактов (включая rcall и ret)
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
Square_16: ; Подгрузка в регистры квадратов младшего и старшего байтов,
; а так же квадрата их разности
mov ZL, r16 ; Загрузка квадрата младшего байта величины
ldi ZH, HIGH(2*SquareTable0)
lpm r18, Z ; Младший байт квадрата
ldi ZH, HIGH(2*SquareTable1)
lpm r19, Z ; Старший байт квадрата
sub ZL, r17 ; Загрузка квадрата разности байтов величины
brcc Square_16_
neg ZL ; Смена знака, если разность отрицательна
Square_16_: lpm r21, Z ; Старший байт квадрата
ldi ZH, HIGH(2*SquareTable0)
lpm r20, Z ; Младший байт квадрата
mov ZL, r17 ; Загрузка квадрата старшего байта величины
lpm r22, Z ; Младший байт квадрата
ldi ZH, HIGH(2*SquareTable1)
lpm r23, Z ; Старший байт квадрата
; Первое сложение с кумулятивной суммой
add r10, r18 ; Младший байт квадрата младшего байта
adc r11, r19 ; Старший байт квадрата младшего байта
adc r12, r22 ; Младший байт квадрата старшего байта
adc r13, r23 ; Старший байт квадрата старшего байта
adc r14, zero ; Перенос
; Расчёт удвоенного произведения старшего и младшего байтов величины
clr r24
add r22, r18 ; Сумма квадратов
adc r23, r19
adc r24, zero
sub r22, r20 ; Вычитание квадрата разности
sbc r23, r21
sbc r24, zero
; Второе сложение с кумулятивной суммой
add r11, r22 ; Младший байт удвоенного произведения
adc r12, r23 ; Старший байт удвоенного произведения
adc r13, r24 ; Невлезающий бит удвоенного произведения
adc r14, zero ; Перенос
ret
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
Код под катом в 2 раза быстрее и меньше по размеру 200-доковской процедуры, оптимизированной под скорость, и в 3 раза быстрее компактной процедуры с циклом. С трёхбайтной величиной выигрыш, мне думается, будет ещё больше.
Шпаргалка к процедуре:
- Вложения
-
- TwobyteSquare.png
- (1.02 KiB) Скачиваний: 610
Последний раз редактировалось B@R5uk Сб апр 09, 2022 09:43:09, всего редактировалось 2 раз(а).
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 09:01:47
Блин. Старею что ли.B@R5uk писал(а):...Затребовалось мне посчитать сумму квадратов трёхбайтных величин...
По мне, сумма квадратов выражается a²+b²+c² Хотелось бы узнать сколько в результате получится циклов при максимальных трехбайтных беззнаковых величин.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 09:31:24
akl, извиняюсь, что недостаточно ясно объяснил задачу. Одна трёх-байтна величина — это
65536 a + 256 b + c,
где a, b и c — это, соответственно, старший, средний и младший байты этой величины. У меня их много:
65536 a_i + 256 b_i + c_i;
каждую из них надо возвести в квадрат и просуммировать:
Σ (65536 a_i + 256 b_i + c_i)^2.
В формуле в первом посте разложен на компоненты квадрат лишь одного слагаемого.
 А в чём разница?
А в чём разница?
65536 a + 256 b + c,
где a, b и c — это, соответственно, старший, средний и младший байты этой величины. У меня их много:
65536 a_i + 256 b_i + c_i;
каждую из них надо возвести в квадрат и просуммировать:
Σ (65536 a_i + 256 b_i + c_i)^2.
В формуле в первом посте разложен на компоненты квадрат лишь одного слагаемого.
...в AVR нет тактов, есть только циклы.
А в чём разница?
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 10:07:53
Спойлер
- Код:
; Проба определения числа циклов вычисления суммы квадратов.
; 09.04.2022
.INCLUDE "tn2313def.inc"
RESET:
LDI ZL,LOW(RAMEND)
OUT SPL,ZL
CLR R24
CLR R25
CLR R26
SER R27
SER R28
SER R29
MOV R4,R24
MOV R5,R25
MOV R6,R26
MOV R7,R27
MOV R8,R28
MOV R9,R29
MOV R14,R24
MOV R15,R25
MOV R16,R26
MOV R17,R27
MOV R18,R28
MOV R19,R29
RCALL MULT_48
PUSH R29
PUSH R28
PUSH R27
PUSH R26
PUSH R25
PUSH R24
CLR R24
CLR R25
CLR R26
SER R27
SER R28
SER R29
MOV R4,R24
MOV R5,R25
MOV R6,R26
MOV R7,R27
MOV R8,R28
MOV R9,R29
MOV R14,R24
MOV R15,R25
MOV R16,R26
MOV R17,R27
MOV R18,R28
MOV R19,R29
RCALL MULT_48
PUSH R29
PUSH R28
PUSH R27
PUSH R26
PUSH R25
PUSH R24
CLR R24
CLR R25
CLR R26
SER R27
SER R28
SER R29
MOV R4,R24
MOV R5,R25
MOV R6,R26
MOV R7,R27
MOV R8,R28
MOV R9,R29
MOV R14,R24
MOV R15,R25
MOV R16,R26
MOV R17,R27
MOV R18,R28
MOV R19,R29
RCALL MULT_48
;
POP R4
POP R5
POP R6
POP R7
POP R8
POP R9
CLR R23
CLR ZH
ADD R29,R9
ADC R28,R8
ADC R27,R7
ADC R26,R6
ADC R25,R5
ADC R24,R4
ADC R23,ZH
POP R4
POP R5
POP R6
POP R7
POP R8
POP R9
ADD R29,R9
ADC R28,R8
ADC R27,R7
ADC R26,R6
ADC R25,R5
ADC R24,R4
ADC R23,ZH
RJMP RESET
; Программа умножения 48 разрядного числа на 48 разрядное число
; Для получения корректного результата сумма разрядов множимого и множителя должна быть меньше 80
; R4...R9-MNOGIMOE,R14...R19-MNOGITEL,R24...R29-RAB
; R4...R9-RESULT
; R24...R29-RESULT
; ZL(R30)-TEMP
;************************************************
MULT_48:
; CLT ; сбос флага ошибки, если это не было сделано при входе в программу
LDI ZL,48 ; установить счетчик сдвигов
CLR R24
CLR R25
CLR R26
CLR R27
CLR R28
CLR R29 ; начальное значение результата
OBRAT_48:
LSR R14
ROR R15
ROR R16
ROR R17
ROR R18
ROR R19 ; показать значение младшего разряда множителя в С,
BRCC NO_SUMMIR_48 ; С=0 пропустить суммирование
SUMMIR_48:
; С=1 суммировать значение множимого с частичным результатом
ADD R29,R9
ADC R28,R8
ADC R27,R7
ADC R26,R6
ADC R25,R5
ADC R24,R4
NO_SUMMIR_48:
LSL R9
ROL R8
ROL R7
ROL R6
ROL R5
ROL R4 ; множимое*2
DEC ZL
BRNE OBRAT_48
; MOV R4,R24
; MOV R5,R25
; MOV R6,R26
; MOV R7,R27
; MOV R8,R28
; MOV R9,R29
RET
;ERROR_MULT:
; SET
; RET
;**********************************************************************
.EXIT
Линейная программа суммы квадратов максимальных беззнаковых трехбайтных величин занимает 2967 циклов. Результат в R23...R29 в формате старший младший.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 10:43:54
например, в самых первых МК 51-го семейства машинный цикл состоял из 12 машинных тактов. при дальнейшем развитии этого семейства цикл сократили до 6 тактов. и все эти такты можно было воочию наблюдать на выводах этих МК.B@R5uk писал(а):А в чём разница?
а что делается во время цикла в авровских МК, нам неизвестно, так как снаружи мы этого не видим.
и в документации на всё семейство AVR говорится только о циклах, о тактах даже упоминания нет.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 11:13:23
Starichok51, спасибо, теперь понятно.
Спойлер
Но вот в даташите пишут:"Clock cycle", как по мне, в этом контексте весьма логично переводить как тактовый период, тактовый цикл или просто как такт. В любом случае, для этого МК такт = цикл, что я, конечно, понимаю, в общем случае не верно.2. Overview
The ATtiny2313A/4313 is a low-power CMOS 8-bit microcontroller based on the AVR enhanced
RISC architecture. By executing powerful instructions in a single clock cycle, the
ATtiny2313A/4313 achieves throughputs approaching 1 MIPS per MHz allowing the system
designer to optimize power consumption versus processing speed.
...а что делается во время цикла в авровских МК, нам неизвестно, так как снаружи мы этого не видим.
В разделе 4.6 Instruction Execution Timing довольно подробно и с диаграммами расписывается, как происходят выборка и выполнение инструкций и из каких стадий состоит само выполнение....занимает 2967 циклов...
Три умножения за три тысячи тактов. Это по тысяче тактов на одно умножение. Как-то слишком уж медленно. Мне бы хотя бы раз в 5 бы быстрее.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 15:29:47
Может нужно начать от печки. Откуда начальные значения? Для чего нужно умножать и возводить в квадрат?
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 18:22:33
pyzhman, не стоит сильно уж оффтопить. Задача поставлена и сама по себе представляет интерес.

Сразу говорю: возможности воспользоваться другим чипом у меня нет от слова совсем. Впрочем, не велика беда, ресурсов этого пока хватает.
Впрочем, не велика беда, ресурсов этого пока хватает.
Сделал предварительный набросок процедуры для трёхбайтных данных (время выполнения 126 тактов):
Теперь бы надо как-то перетусовать операции, чтобы уменьшить расход регистром CPU до божеских 8-12 штук. Можно даже пожертвовать быстродействием немного, а так же позволить процедуре затереть исходную величину.
Кто-нибудь знает программу-оптимизатор ассемблерного кода, способную справиться с этой задачей?
Спойлер
Если вам действительно интересно, то данные приходят с таймера, а вычисления нужны для получения статистики. Надеюсь, вы не будете переубеждать меня, что мне это нужно?Сразу говорю: возможности воспользоваться другим чипом у меня нет от слова совсем.
Сделал предварительный набросок процедуры для трёхбайтных данных (время выполнения 126 тактов):
Спойлер
- Код:
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.def zero = r0
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.dseg
CSum: .byte 8
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.cseg
clr zero
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
; Процедура возводит в квадрат трёхбайтную величину (2^16 A + 2^8 B + C)
; и добавляет результат к кумулятивной сумме в оперативной памяти
; | 47-40 | 39-32 | 31-24 | 23-16 | 15-8 | 7-0 |
; [ C^2 ]
; [ B^2+C^2-(B-C)^2 ]
; [ B^2 ]
; [ A^2+C^2-(A-C)^2 ]
; [ A^2+B^2-(A-B)^2 ]
; [ A^2 ]
; Используемые регистры:
; - r16 - r18 - исходная величина (3 байта)
; - r2 - r15 - вспомогательные регистры для промежуточных данных
; - r19 - r25 - вспомогательные регистры для кумулятивной суммы
; - zero - глобальный (для всей программы) регистр с нулевым значением
; Размер процедуры 192 байта (82 инструкции)
; Время выполнения 126 тактов (включая rcall и ret)
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
Square_24: ; Подгрузка в регистры промежуточных квадратов
mov ZL, r17 ; Байт B
ldi ZH, HIGH(2*SquareTable0)
lpm r6, Z ; Младший байт B^2
ldi ZH, HIGH(2*SquareTable1)
lpm r7, Z ; Старший байт B^2
sub ZL, r16 ; Разность B - C
brcc Square_24_1
neg ZL ; Модуль разности |B - C|
Square_24_1: lpm r11, Z ; Старший байт (B - C)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r10, Z ; Младший байт (B - C)^2
mov ZL, r16 ; Байт C
lpm r4, Z ; Младший байт C^2
ldi ZH, HIGH(2*SquareTable1)
lpm r5, Z ; Старший байт C^2
sub ZL, r18 ; Разность C - A
brcc Square_24_2
neg ZL ; Модуль разности |A - C|
Square_24_2: lpm r13, Z ; Старший байт (A - C)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r12, Z ; Младший байт (A - C)^2
mov ZL, r18 ; Байт A
lpm r8, Z ; Младший байт A^2
ldi ZH, HIGH(2*SquareTable1)
lpm r9, Z ; Старший байт A^2
sub ZL, r17 ; Разность A - B
brcc Square_24_3
neg ZL ; Модуль разности |A - B|
Square_24_3: lpm r15, Z ; Старший байт (A - B)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r14, Z ; Младший байт (A - B)^2
; Подгрузка кумулятивной суммы
lds r19, CSum+0
lds r20, CSum+1
lds r21, CSum+2
lds r22, CSum+3
lds r23, CSum+4
lds r24, CSum+5
lds r25, CSum+6
; Первое сложение с кумулятивной суммой
add r19, r4 ; C^2
adc r20, r5
adc r21, r6 ; B^2
adc r22, r7
adc r23, r8 ; A^2
adc r24, r9
adc r25, zero ; Перенос
; Второе сложение с кумулятивной суммой
clr r3
add r20, r4 ; C^2
adc r21, r5
adc r22, r6 ; B^2
adc r23, r7
adc r3, zero ; Перенос
; Третье сложение с кумулятивной суммой
add r20, r6 ; B^2
adc r21, r7
adc r22, r8 ; A^2
adc r23, r9
adc r3, zero ; Перенос
; Первое вычитание из кумулятивной суммы
sub r20, r10 ; (B - C)^2
sbc r21, r11
sbc r22, r14 ; (A - B)^2
sbc r23, r15
sbc r3, zero ; Перенос
; Оставшиеся операции над центральной частью кумулятивной суммы
clr r2
add r21, r4 ; C^2
adc r22, r5
adc r2, zero ; Перенос
add r21, r8 ; A^2
adc r22, r9
adc r2, zero ; Перенос
sub r21, r12 ; (A - C)^2
sbc r22, r13
sbc r2, zero ; Перенос
; Добавление сохранённых переносов
add r23, r2
adc r24, r3
adc r25, zero
; Сохранение полученного результата в ОЗУ
sts CSum+0, r19
sts CSum+1, r20
sts CSum+2, r21
sts CSum+3, r22
sts CSum+4, r23
sts CSum+5, r24
sts CSum+6, r25
ret
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
Теперь бы надо как-то перетусовать операции, чтобы уменьшить расход регистром CPU до божеских 8-12 штук. Можно даже пожертвовать быстродействием немного, а так же позволить процедуре затереть исходную величину.
Кто-нибудь знает программу-оптимизатор ассемблерного кода, способную справиться с этой задачей?
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 19:13:00
Не знаю, что конкретно у Вас, но, может, эта формула поможет..
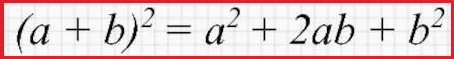
- Вложения
-
- 1.png
- (29.11 KiB) Скачиваний: 477
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 19:59:18
Карбофос, сумма за пределы таблицы выходит. Искать квадрат (модуля) разности гораздо практичнее.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Сб апр 09, 2022 23:23:38
Рекуррентное вычисление квадрата. a - предыдущее значение, b - разница.
Добавлено after 3 hours 12 minutes 25 seconds:
Re: Умножение и возведение в квадрат без аппаратной поддержки
Допустим, прошло 256 тиков вашего таймера без событий - обновились.
Добавлено after 3 hours 12 minutes 25 seconds:
Re: Умножение и возведение в квадрат без аппаратной поддержки
Допустим, прошло 256 тиков вашего таймера без событий - обновились.
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 06:52:34
Сделал предварительный набросок процедуры для трёхбайтных данных (время выполнения 126 тактов)...
Проверил. Очень понравилось.
Убрал обмен с памятью. Вместо 119 циклов стало 91.
Спойлер
- Код:
.INCLUDE "tn2313def.inc"
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.def zero = r0
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
;.dseg
;CSum: .byte 8
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.cseg
LDI ZH,LOW(RAMEND)
OUT SPL,ZH
CLR R16
CLR R17
LDI R18,$80 ;исходная величина 80 00 00
; CLR R16
; CLR R17
; CLR R18 ;исходная величина 00 00 00
; SER R16
; SER R17
; SER R18 ;исходная величина FF FF FF
CLR zero
CLR R19
CLR R20
CLR R21
CLR R22
CLR R23
CLR R24
CLR R25
; sts CSum+0,zero
; sts CSum+1,zero
; sts CSum+2,zero
; sts CSum+3,zero
; sts CSum+4,zero
; sts CSum+5,zero
; sts CSum+6,zero
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
; Процедура возводит в квадрат трёхбайтную величину (2^16 A + 2^8 B + C)
; и добавляет результат к кумулятивной сумме в оперативной памяти
; | 47-40 | 39-32 | 31-24 | 23-16 | 15-8 | 7-0 |
; [ C^2 ]
; [ B^2+C^2-(B-C)^2 ]
; [ B^2 ]
; [ A^2+C^2-(A-C)^2 ]
; [ A^2+B^2-(A-B)^2 ]
; [ A^2 ]
; Используемые регистры:
; - r16 - r18 - исходная величина (3 байта)
; - r2 - r15 - вспомогательные регистры для промежуточных данных
; - r19 - r25 - вспомогательные регистры для кумулятивной суммы
; - zero - глобальный (для всей программы) регистр с нулевым значением
; Размер процедуры 192 байта (82 инструкции)
; Время выполнения 126 тактов (включая rcall и ret)
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
Square_24: ; Подгрузка в регистры промежуточных квадратов
mov ZL, r17 ; Байт B
ldi ZH, HIGH(2*SquareTable0)
lpm r6, Z ; Младший байт B^2
ldi ZH, HIGH(2*SquareTable1)
lpm r7, Z ; Старший байт B^2
sub ZL, r16 ; Разность B - C
brcc Square_24_1
neg ZL ; Модуль разности |B - C|
Square_24_1: lpm r11, Z ; Старший байт (B - C)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r10, Z ; Младший байт (B - C)^2
mov ZL, r16 ; Байт C
lpm r4, Z ; Младший байт C^2
ldi ZH, HIGH(2*SquareTable1)
lpm r5, Z ; Старший байт C^2
sub ZL, r18 ; Разность C - A
brcc Square_24_2
neg ZL ; Модуль разности |A - C|
Square_24_2: lpm r13, Z ; Старший байт (A - C)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r12, Z ; Младший байт (A - C)^2
mov ZL, r18 ; Байт A
lpm r8, Z ; Младший байт A^2
ldi ZH, HIGH(2*SquareTable1)
lpm r9, Z ; Старший байт A^2
sub ZL, r17 ; Разность A - B
brcc Square_24_3
neg ZL ; Модуль разности |A - B|
Square_24_3: lpm r15, Z ; Старший байт (A - B)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r14, Z ; Младший байт (A - B)^2
; Подгрузка кумулятивной суммы
; lds r19, CSum+0
; lds r20, CSum+1
; lds r21, CSum+2
; lds r22, CSum+3
; lds r23, CSum+4
; lds r24, CSum+5
; lds r25, CSum+6
; Первое сложение с кумулятивной суммой
add r19, r4 ; C^2
adc r20, r5
adc r21, r6 ; B^2
adc r22, r7
adc r23, r8 ; A^2
adc r24, r9
adc r25, zero ; Перенос
; Второе сложение с кумулятивной суммой
clr r3
add r20, r4 ; C^2
adc r21, r5
adc r22, r6 ; B^2
adc r23, r7
adc r3, zero ; Перенос
; Третье сложение с кумулятивной суммой
add r20, r6 ; B^2
adc r21, r7
adc r22, r8 ; A^2
adc r23, r9
adc r3, zero ; Перенос
; Первое вычитание из кумулятивной суммы
sub r20, r10 ; (B - C)^2
sbc r21, r11
sbc r22, r14 ; (A - B)^2
sbc r23, r15
sbc r3, zero ; Перенос
; Оставшиеся операции над центральной частью кумулятивной суммы
clr r2
add r21, r4 ; C^2
adc r22, r5
adc r2, zero ; Перенос
add r21, r8 ; A^2
adc r22, r9
adc r2, zero ; Перенос
sub r21, r12 ; (A - C)^2
sbc r22, r13
sbc r2, zero ; Перенос
; Добавление сохранённых переносов
add r23, r2
adc r24, r3
adc r25, zero
; Сохранение полученного результата в ОЗУ
; sts CSum+0, r19
; sts CSum+1, r20
; sts CSum+2, r21
; sts CSum+3, r22
; sts CSum+4, r23
; sts CSum+5, r24
; sts CSum+6, r25
RJMP Square_24
; ret
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.org 0x0300
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
SquareTable0: .dw 0x0100, 0x0904, 0x1910, 0x3124, 0x5140, 0x7964, 0xA990, 0xE1C4
.dw 0x2100, 0x6944, 0xB990, 0x11E4, 0x7140, 0xD9A4, 0x4910, 0xC184
.dw 0x4100, 0xC984, 0x5910, 0xF1A4, 0x9140, 0x39E4, 0xE990, 0xA144
.dw 0x6100, 0x29C4, 0xF990, 0xD164, 0xB140, 0x9924, 0x8910, 0x8104
.dw 0x8100, 0x8904, 0x9910, 0xB124, 0xD140, 0xF964, 0x2990, 0x61C4
.dw 0xA100, 0xE944, 0x3990, 0x91E4, 0xF140, 0x59A4, 0xC910, 0x4184
.dw 0xC100, 0x4984, 0xD910, 0x71A4, 0x1140, 0xB9E4, 0x6990, 0x2144
.dw 0xE100, 0xA9C4, 0x7990, 0x5164, 0x3140, 0x1924, 0x0910, 0x0104
.dw 0x0100, 0x0904, 0x1910, 0x3124, 0x5140, 0x7964, 0xA990, 0xE1C4
.dw 0x2100, 0x6944, 0xB990, 0x11E4, 0x7140, 0xD9A4, 0x4910, 0xC184
.dw 0x4100, 0xC984, 0x5910, 0xF1A4, 0x9140, 0x39E4, 0xE990, 0xA144
.dw 0x6100, 0x29C4, 0xF990, 0xD164, 0xB140, 0x9924, 0x8910, 0x8104
.dw 0x8100, 0x8904, 0x9910, 0xB124, 0xD140, 0xF964, 0x2990, 0x61C4
.dw 0xA100, 0xE944, 0x3990, 0x91E4, 0xF140, 0x59A4, 0xC910, 0x4184
.dw 0xC100, 0x4984, 0xD910, 0x71A4, 0x1140, 0xB9E4, 0x6990, 0x2144
.dw 0xE100, 0xA9C4, 0x7990, 0x5164, 0x3140, 0x1924, 0x0910, 0x0104
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
SquareTable1: .dw 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000, 0x0000
.dw 0x0101, 0x0101, 0x0101, 0x0201, 0x0202, 0x0202, 0x0303, 0x0303
.dw 0x0404, 0x0404, 0x0505, 0x0505, 0x0606, 0x0706, 0x0707, 0x0808
.dw 0x0909, 0x0A09, 0x0A0A, 0x0B0B, 0x0C0C, 0x0D0D, 0x0E0E, 0x0F0F
.dw 0x1010, 0x1111, 0x1212, 0x1313, 0x1414, 0x1515, 0x1716, 0x1817
.dw 0x1919, 0x1A1A, 0x1C1B, 0x1D1C, 0x1E1E, 0x201F, 0x2121, 0x2322
.dw 0x2424, 0x2625, 0x2727, 0x2928, 0x2B2A, 0x2C2B, 0x2E2D, 0x302F
.dw 0x3131, 0x3332, 0x3534, 0x3736, 0x3938, 0x3B3A, 0x3D3C, 0x3F3E
.dw 0x4140, 0x4342, 0x4544, 0x4746, 0x4948, 0x4B4A, 0x4D4C, 0x4F4E
.dw 0x5251, 0x5453, 0x5655, 0x5957, 0x5B5A, 0x5D5C, 0x605F, 0x6261
.dw 0x6564, 0x6766, 0x6A69, 0x6C6B, 0x6F6E, 0x7270, 0x7473, 0x7776
.dw 0x7A79, 0x7D7B, 0x7F7E, 0x8281, 0x8584, 0x8887, 0x8B8A, 0x8E8D
.dw 0x9190, 0x9493, 0x9796, 0x9A99, 0x9D9C, 0xA09F, 0xA4A2, 0xA7A5
.dw 0xAAA9, 0xADAC, 0xB1AF, 0xB4B2, 0xB7B6, 0xBBB9, 0xBEBD, 0xC2C0
.dw 0xC5C4, 0xC9C7, 0xCCCB, 0xD0CE, 0xD4D2, 0xD7D5, 0xDBD9, 0xDFDD
.dw 0xE2E1, 0xE6E4, 0xEAE8, 0xEEEC, 0xF2F0, 0xF6F4, 0xFAF8, 0xFEFC
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.EXIT
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 09:13:00
Кстати, а как эту задачу решит СИшный компилятор, смотрели?
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 10:10:45
Gudd-Head, не-а. Хотя мне очень-очень интересно, что он выдаст.
 По идее надо скомпилировать на скорость и экономию регистров вот такой код:
По идее надо скомпилировать на скорость и экономию регистров вот такой код:
Если кому не лень скомпилить и поделиться со всеми, буду очень благодарен. 
Шпаргалка к коду:
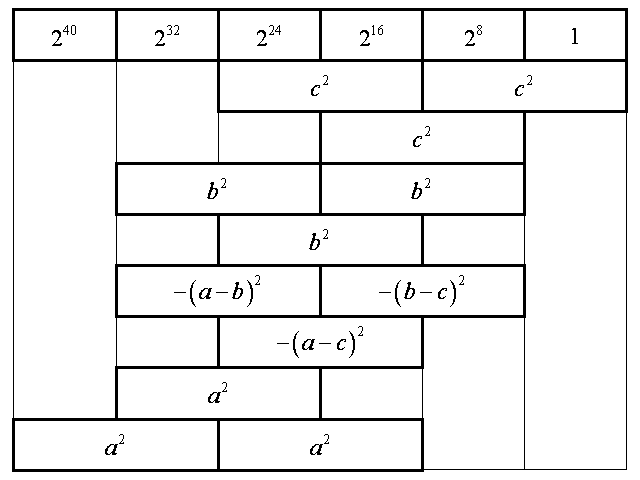
Спойлер
Я, к своему стыду, так сишный компилятор к AVR Studio прикрутить не смог. Как-то один раз попробовал, не взлетело, да и забил. На асме пока всё, что нужно, делалось. Даже операции с плавающей точкой.Спойлер
- Код:
#define abs(x) (((x) < 0 ) ? (-(x)) : (x))
unit8_t [] SquareTable0 = {
0x00, 0x01, 0x04, 0x09, 0x10, 0x19, 0x24, 0x31, 0x40, 0x51, 0x64, 0x79, 0x90, 0xA9, 0xC4, 0xE1,
0x00, 0x21, 0x44, 0x69, 0x90, 0xB9, 0xE4, 0x11, 0x40, 0x71, 0xA4, 0xD9, 0x10, 0x49, 0x84, 0xC1,
0x00, 0x41, 0x84, 0xC9, 0x10, 0x59, 0xA4, 0xF1, 0x40, 0x91, 0xE4, 0x39, 0x90, 0xE9, 0x44, 0xA1,
0x00, 0x61, 0xC4, 0x29, 0x90, 0xF9, 0x64, 0xD1, 0x40, 0xB1, 0x24, 0x99, 0x10, 0x89, 0x04, 0x81,
0x00, 0x81, 0x04, 0x89, 0x10, 0x99, 0x24, 0xB1, 0x40, 0xD1, 0x64, 0xF9, 0x90, 0x29, 0xC4, 0x61,
0x00, 0xA1, 0x44, 0xE9, 0x90, 0x39, 0xE4, 0x91, 0x40, 0xF1, 0xA4, 0x59, 0x10, 0xC9, 0x84, 0x41,
0x00, 0xC1, 0x84, 0x49, 0x10, 0xD9, 0xA4, 0x71, 0x40, 0x11, 0xE4, 0xB9, 0x90, 0x69, 0x44, 0x21,
0x00, 0xE1, 0xC4, 0xA9, 0x90, 0x79, 0x64, 0x51, 0x40, 0x31, 0x24, 0x19, 0x10, 0x09, 0x04, 0x01,
0x00, 0x01, 0x04, 0x09, 0x10, 0x19, 0x24, 0x31, 0x40, 0x51, 0x64, 0x79, 0x90, 0xA9, 0xC4, 0xE1,
0x00, 0x21, 0x44, 0x69, 0x90, 0xB9, 0xE4, 0x11, 0x40, 0x71, 0xA4, 0xD9, 0x10, 0x49, 0x84, 0xC1,
0x00, 0x41, 0x84, 0xC9, 0x10, 0x59, 0xA4, 0xF1, 0x40, 0x91, 0xE4, 0x39, 0x90, 0xE9, 0x44, 0xA1,
0x00, 0x61, 0xC4, 0x29, 0x90, 0xF9, 0x64, 0xD1, 0x40, 0xB1, 0x24, 0x99, 0x10, 0x89, 0x04, 0x81,
0x00, 0x81, 0x04, 0x89, 0x10, 0x99, 0x24, 0xB1, 0x40, 0xD1, 0x64, 0xF9, 0x90, 0x29, 0xC4, 0x61,
0x00, 0xA1, 0x44, 0xE9, 0x90, 0x39, 0xE4, 0x91, 0x40, 0xF1, 0xA4, 0x59, 0x10, 0xC9, 0x84, 0x41,
0x00, 0xC1, 0x84, 0x49, 0x10, 0xD9, 0xA4, 0x71, 0x40, 0x11, 0xE4, 0xB9, 0x90, 0x69, 0x44, 0x21,
0x00, 0xE1, 0xC4, 0xA9, 0x90, 0x79, 0x64, 0x51, 0x40, 0x31, 0x24, 0x19, 0x10, 0x09, 0x04, 0x01
};
unit8_t [] SquareTable1 = {
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x01, 0x02, 0x02, 0x02, 0x02, 0x02, 0x03, 0x03, 0x03, 0x03,
0x04, 0x04, 0x04, 0x04, 0x05, 0x05, 0x05, 0x05, 0x06, 0x06, 0x06, 0x07, 0x07, 0x07, 0x08, 0x08,
0x09, 0x09, 0x09, 0x0A, 0x0A, 0x0A, 0x0B, 0x0B, 0x0C, 0x0C, 0x0D, 0x0D, 0x0E, 0x0E, 0x0F, 0x0F,
0x10, 0x10, 0x11, 0x11, 0x12, 0x12, 0x13, 0x13, 0x14, 0x14, 0x15, 0x15, 0x16, 0x17, 0x17, 0x18,
0x19, 0x19, 0x1A, 0x1A, 0x1B, 0x1C, 0x1C, 0x1D, 0x1E, 0x1E, 0x1F, 0x20, 0x21, 0x21, 0x22, 0x23,
0x24, 0x24, 0x25, 0x26, 0x27, 0x27, 0x28, 0x29, 0x2A, 0x2B, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F, 0x30,
0x31, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3A, 0x3B, 0x3C, 0x3D, 0x3E, 0x3F,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4A, 0x4B, 0x4C, 0x4D, 0x4E, 0x4F,
0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x59, 0x5A, 0x5B, 0x5C, 0x5D, 0x5F, 0x60, 0x61, 0x62,
0x64, 0x65, 0x66, 0x67, 0x69, 0x6A, 0x6B, 0x6C, 0x6E, 0x6F, 0x70, 0x72, 0x73, 0x74, 0x76, 0x77,
0x79, 0x7A, 0x7B, 0x7D, 0x7E, 0x7F, 0x81, 0x82, 0x84, 0x85, 0x87, 0x88, 0x8A, 0x8B, 0x8D, 0x8E,
0x90, 0x91, 0x93, 0x94, 0x96, 0x97, 0x99, 0x9A, 0x9C, 0x9D, 0x9F, 0xA0, 0xA2, 0xA4, 0xA5, 0xA7,
0xA9, 0xAA, 0xAC, 0xAD, 0xAF, 0xB1, 0xB2, 0xB4, 0xB6, 0xB7, 0xB9, 0xBB, 0xBD, 0xBE, 0xC0, 0xC2,
0xC4, 0xC5, 0xC7, 0xC9, 0xCB, 0xCC, 0xCE, 0xD0, 0xD2, 0xD4, 0xD5, 0xD7, 0xD9, 0xDB, 0xDD, 0xDF,
0xE1, 0xE2, 0xE4, 0xE6, 0xE8, 0xEA, 0xEC, 0xEE, 0xF0, 0xF2, 0xF4, 0xF6, 0xF8, 0xFA, 0xFC, 0xFE,
};
void main () {
unit8_t byte0 = 0xAA, byte1 = 0x55, byte2 = 0xFF;
uint64_t result =
+ ((uint64_t) (SquareTable0 [byte0]))
+ ((uint64_t) (SquareTable1 [byte0])) << 8
+ ((uint64_t) (SquareTable0 [byte0])) << 8
+ ((uint64_t) (SquareTable1 [byte0])) << 16
+ ((uint64_t) (SquareTable0 [byte0])) << 16
+ ((uint64_t) (SquareTable1 [byte0])) << 24
+ ((uint64_t) (SquareTable0 [byte1])) << 8
+ ((uint64_t) (SquareTable1 [byte1])) << 16
+ ((uint64_t) (SquareTable0 [byte1])) << 16
+ ((uint64_t) (SquareTable1 [byte1])) << 24
+ ((uint64_t) (SquareTable0 [byte1])) << 24
+ ((uint64_t) (SquareTable1 [byte1])) << 32
+ ((uint64_t) (SquareTable0 [byte2])) << 16
+ ((uint64_t) (SquareTable1 [byte2])) << 24
+ ((uint64_t) (SquareTable0 [byte2])) << 24
+ ((uint64_t) (SquareTable1 [byte2])) << 32
+ ((uint64_t) (SquareTable0 [byte2])) << 32
+ ((uint64_t) (SquareTable1 [byte2])) << 40
- ((uint64_t) (SquareTable0 [abs (byte0 - byte1)])) << 8
- ((uint64_t) (SquareTable1 [abs (byte0 - byte1)])) << 16
- ((uint64_t) (SquareTable0 [abs (byte0 - byte2)])) << 16
- ((uint64_t) (SquareTable1 [abs (byte0 - byte2)])) << 24
- ((uint64_t) (SquareTable0 [abs (byte1 - byte2)])) << 24
- ((uint64_t) (SquareTable1 [abs (byte1 - byte2)])) << 32
}
Шпаргалка к коду:
Спойлер
- Вложения
-
- TribyteSquareExtended.png
- (1.62 KiB) Скачиваний: 110
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 12:40:13
и в документации на всё семейство AVR говорится только о циклах, о тактах даже упоминания нет.
Может, у нас разные документации ?
pyzhman, не стоит сильно уж оффтопить.
А мне не кажется таким уж офтопом. Одно из правил ТРИЗ гласит: при оптимизации операции первое, что надо рассмотреть: а нельзя ли вообще обойтись без этой операции. Конечно, ТСу виднее, обсуждать тут не резон, но квадраты 3-байтных чисел, да ещё в прерывании...
Правда, если частота прерываний - 50Гц, то можно успеть.
А задача утоптать алгоритм в 5 раз мне представляется маловероятой на данном железе. Уж выбачайце за пессимизм. Хотя самому приходилось бороться за каждую микросекунду... Вспомню - вздрогну.
- Вложения
-
- Циклы.JPG
- (10.27 KiB) Скачиваний: 373
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 13:38:21
через букву "Т" обозначены не такты внутри цикла, а такты внешней тактовой частоты.Jack_A писал(а):Может, у нас разные документации ?
из этой картинки (в нижней части) прекрасно видно, время выполнения цикла равно одному такту внешней тактовой частоты.
у меня есть давно предположение, что внутри есть умножитель частоты, который и создает некоторое количество тактов внутри МК за 1 такт внешней тактовой частоты.
вот, если бы ты нашел картинку, где разрисованы процессы внутри цикла ...
Re: Умножение и возведение в квадрат без аппаратной поддержк
Вс апр 10, 2022 16:22:51
Правда, если частота прерываний - 50Гц, то можно успеть.
А задача утоптать алгоритм в 5 раз мне представляется маловероятой на данном железе.
Вот те пополам! Вы почитайте сообщения то по-внимательней! Представлен же вариант процедуры, которая в 8 раз быстрее! А чуть ниже (если отказаться от обращения к ОЗУ) то во все 11 раз!А задача утоптать алгоритм в 5 раз мне представляется маловероятой на данном железе.
Starichok51
Спойлер
...у меня есть давно предположение, что внутри есть умножитель частоты...
Ваше подозрение вполне себе обосновано:Добавлено after 59 minutes 7 seconds:
Убрал обмен с памятью. Вместо 119 циклов стало 91.
Да, пожалуй это здравая мысля. Кумулятивная сумма обновляется каждое прерывание, поэтому её логичнее хранить в регистровом файле.Отполировал немного свою процедуру. Пришлось добавить одно обращение к стеку (пара Push/pop), но за то теперь вместо 27 регистров задействовано только 18, причём 7 из них хранят кумулятивную сумму, а 3 (zero и указатель Z) являются расшаренным ресурсом. Экономия! Как-то более плотно упаковать вычисления мне что-то не видится возможным без заметной потери производительности. Время работы 102 цикла.
Спойлер
- Код:
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
.def zero = r0
.def csum0 = r9
.def csum1 = r10
.def csum2 = r11
.def csum3 = r12
.def csum4 = r13
.def csum5 = r14
.def csum6 = r15
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
; Процедура возводит в квадрат трёхбайтную величину (2^16 A + 2^8 B + C)
; и добавляет результат к кумулятивной сумме
; Используемые ресурсы:
; - zero - глобальный (для всей программы) регистр с нулевым значением
; - r16 - r18 - исходная величина (3 байта, затирается в процессе работы)
; - csum0 - csum6
; - кумулятивная сумма, к которой добавляется результат работы
; - r19 - r23 - вспомогательные регистры для промежуточных данных (5 штук)
; - Z - указатель на таблицу квадратов в ПЗУ
; - STACK - 1 байт стека
; Размер процедуры 140 байт (70 инструкций)
; Время выполнения 102 такта (включая rcall и ret)
;--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--
Square_24a: ; Подгрузка в регистры промежуточных квадратов
mov ZL, r18 ; Байт A
ldi ZH, HIGH(2*SquareTable1)
lpm r23, Z ; Старший байт A^2
ldi ZH, HIGH(2*SquareTable0)
lpm r22, Z ; Младший байт A^2
sub ZL, r17 ; Разность A - B
brcc Square_24a_1
neg ZL ; Модуль разности |A - B|
Square_24a_1: push ZL ; Сохранение |A - B| в стек
mov ZL, r16 ; Байт C
ldi ZH, HIGH(2*SquareTable1)
lpm r21, Z ; Старший байт C^2
ldi ZH, HIGH(2*SquareTable0)
lpm r20, Z ; Младший байт C^2
sub ZL, r18 ; Разность C - A
brcc Square_24a_2
neg ZL ; Модуль разности |A - C|
Square_24a_2: ; Вычитание центрального квадрата разности
lpm r18, Z ; Младший байт (A - C)^2
sub csum2, r18
ldi ZH, HIGH(2*SquareTable1)
lpm r18, Z ; Старший байт (A - C)^2
sbc csum3, r18
sbc r18, r18 ; Регистр для переноса/заёма
; Сложения, соответствующие центральному квадрату разности
add csum0, r20 ; C^2
adc csum1, r21
adc csum2, r22 ; A^2
adc csum3, r23
adc r18, zero ; Перенос
add csum2, r20 ; C^2
adc csum3, r21
adc r18, zero ; Перенос теперь гарантированно >= 0
; Подгрузка и вычитание двух боковых квадратов разностей
mov ZL, r17 ; Байт B
sub ZL, r16 ; Разность B - C
brcc Square_24a_3
neg ZL ; Модуль разности |B - C|
Square_24a_3: lpm r19, Z ; Старший байт (B - C)^2
ldi ZH, HIGH(2*SquareTable0)
lpm r16, Z ; Младший байт (B - C)^2
sub csum1, r16
sbc csum2, r19
pop ZL ; Извлечение |A - B| из стека
lpm r19, Z ; Младший байт (A - B)^2
sbc csum3, r19
ldi ZH, HIGH(2*SquareTable1)
lpm r19, Z ; Старший байт (A - B)^2
sbc csum4, r19
sbc r19, r19 ; Регистр для переноса/заёма
; Сложения, соответствующие боковым квадратам разностей
add csum1, r20 ; C^2
adc csum2, r21
adc csum3, r22 ; A^2
adc csum4, r23
adc r19, zero ; Перенос
mov ZL, r17 ; Байт B
lpm r21, Z ; Старший байт B^2
ldi ZH, HIGH(2*SquareTable0)
lpm r20, Z ; Младший байт B^2
add csum1, r20 ; B^2
adc csum2, r21
adc csum3, r20 ; B^2
adc csum4, r21
adc r19, zero ; Перенос теперь гарантированно >= 0
; Сложение с кумулятивной суммой оставшихся двух квадратов
add csum2, r20 ; B^2
adc csum3, r21
adc csum4, r22 ; A^2
adc csum5, r23
adc csum6, zero ; Перенос
; Сложение с кумулятивной суммой сохранённых переносов
add csum4, r18
adc csum5, r19
adc csum6, zero
ret
;==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==-==
Шпаргалка к процедуре всё та же:
Добавлено after 47 minutes 15 seconds:
Теперь мне требуется организовать возведение в квадрат 4-байтной величины и умножение 3-байтной на 7-байтную. С одной стороны, к этим процедурам уже нет требования на быстродействие, поэтому их, в принципе, можно было бы организовать обычным умножением сдвигами в цикле. А с другой, — моё внутреннее чувство перфекционизма корёжится от такой мысли. "Быть или не быть?" — вот в чём вопрос.
- Вложения
-
- TribyteSquareExt.png
- (985 байт) Скачиваний: 325
-
- Figure 4.5.png
- (2.19 KiB) Скачиваний: 88