Re: Ассемблер для STM32. Сложно ли, стоит ли пытаться?
Вс янв 03, 2021 23:12:24
Сравнивай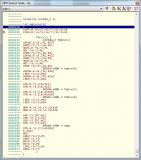
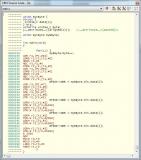
Спойлер
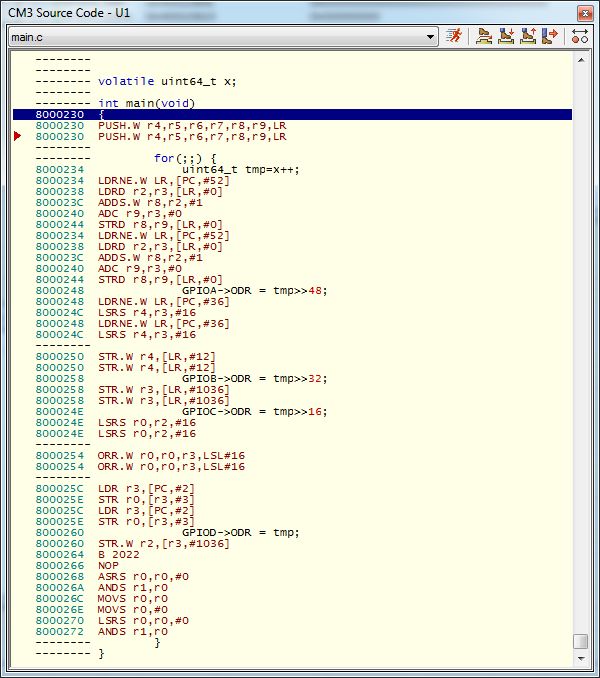
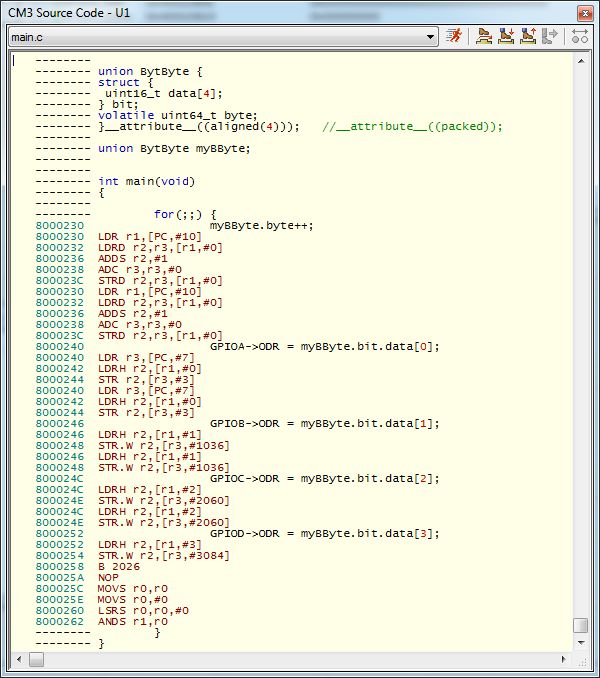
Re: Ассемблер для STM32. Сложно ли, стоит ли пытаться?
Вс янв 03, 2021 23:21:05
Я же всё показал. Сравнивай сам.
Re: Ассемблер для STM32. Сложно ли, стоит ли пытаться?
Пт янв 08, 2021 01:18:30
Поигрался я с идеей iddqd, есть 2 варианта:
1 вариант, когда пины располагаются на одном порту, не важно в какой последовательности.
ОЗУ на один пин 4 байта, на 8 пинов 32 байта.
Технически на 1 пин - 1 бит на порцию, если -> ODR или 2 бита, если -> BSRR. В допущении port-wide доступа. Port-wide доступ имеет смысл например если там LCD с 8-bit bus развесили или например большая группа светодиодов, etc. В принципе с BSRR это битовая маска + latch, так что можно и меньше пинов за раз ворочать, с ухучшением КПД этой операции.1 вариант, когда пины располагаются на одном порту, не важно в какой последовательности.
ОЗУ на один пин 4 байта, на 8 пинов 32 байта.
Любую идею можно довести до маразма. Слать можно отдельные регионы картинки/небольшие иконки/инициализацию дисплея/etc и размер может быть вменяемым. Кстати и ряд других коммуникаций недурно смотрится в виде make packet -> queue send, а пока оно там send можно чем-то еще заняться. И если там всякое сжатие, ну тогда после decompress и "prepare buffer" из вон того куска наверное ок? А какие еще варианты? Если контроллер шины есть то все просто, но он только в очень разлапистых камнях, они дорогие и роутить печатку заманаешься, в общем это сразу повышает планку. А без него вообще какие варианты? Софтом ногодрыгать? Так это вообще блокирующая операция, на ее время проц недееспособен толком (минус IRQ). А, ну еще RTOS можно, но я не знаю как там с таймингами шины будет, в такие дебри я лезть не собираюсь. Мне от MK нужен нижний уровень и предсказуемость, а не высокие абстракции.Если хранить картинку 256*256 точек, да в добавок в цветном изображении, параллельный порт 8 пинов, 256*256*3*32 = 6.291.456 байт.?
Есть варианты когда можно совсем без кода. Типа quasi-hardware PWM, когда целый порт ворочается закольцованым DMA без вмешательства софта вообще. Это будет работать даже если процессорное ядро встрянет. Правда оно тогда не сможет параметры подкручивать, но если это не требовалось, то там целиком железки без участия процессора смогут все сделать.Ну как так можно без кода обойтись? Ведь еще сжать картинку можно, без кода ни как.
1 пин не эффективно по КПД операции. Оно может ВЕСЬ ПОРТ за транзакцию кантовать. Но да, это потребует определенных компромиссов. Оптимальнее всего выделить весь порт под такое развлечение. А почему бы хардвару не сделать хардвару и софту удобно и быстро?. И да, data -> ODR будет с КПД вплоть до 100%. В BSRR только до 50%, битов в 2 раза больше. Зато есть latch, можно только некоторые биты ворочать. Это даже может сосуществовать с некоторой периферией - AFIO в общем случае не очень интересует что там GPIO пытался вообще изобразить. А какое дело какому-нибудь uart input'у до его бита в ODR?Значит дма будем запускать только на один пин, а в прерывании выключать канал,
Вы кажется не поняли. Суть идеи: в RAM или Flash заводится буфер. Он описывает sequencing группы пинов. Типа эволюции состояния порта во времени. И конечно же трансферов при этом должно быть уж точно не 1. Иначе нахрена б такое счастье с сетапом DMA. И да, поскольку DMA отпускает шину чтобы процу что-то дать, он рекорд скорости может и не поставит. Но есть одна killer feature. Мы можем "зарядить отправку пакета" или даже "закольцевать отправку буфера" - и заняться своими делами! DMA асинхронен относительно кода проца. Так что основной профит - в асинхронщине этого относительно процессора и подпертости железом. А отсутствие трафика кода по шинам для этой активности - приятный побочный эффект, DMA не процессор, ему для ворочания порции данных не надо инструкции по шине гонять. Если хочется именно 1 бит, именно DMA, ну, не знаю, SPI какой поюзайте, чтоли. Он видите ли десереализует то что в него вгрузили, так КПД операции сильно интереснее, а послать опять же можно "целый пакет" и даже, вероятно, закольцевать, если это за каким-то чертом надо.А теперь вопрос в практическом применении, для чего и за чем? И где тут выигрыш в скорости?
Для того чтобы графику в жк индикатор писать - нужно дма вместе с таймером использовать.
И вас с новым годом. Я попробовал и с mem2mem. Вообще на светодиодах которым я сделал так подобие PWM это прокатило. Но выпадут ли из порта трансферы и прокатят ли уж какие получатся тайминги (дисплею это важно) если расписать "bus seqencing" и весь его пульнуть как mem2mem - вопрос открытый. Желающие могут позырить если у них скоростной многоканальный логический анализатор есть.PWM в микроконтроллере это значительно больше, чем "ногодрыганье" с определенной частотой, и как только начнётся попытка реализовать его полноценную работу, и глянется на блок-схему, то на DMA останется минимум функционала.
Так реализуется только очень базовый вариант PWM, с рядом ограничений. Скажите, а вам никогда не хотелось PWM'нуть сразу МНОГО светодиодов, например? Можно и не PWM'нуть, а "sequence". При том вот так - число выходов "PWM" таки до 16 на порт - и таки в отличие от совсем софтварных эрзацев хорошо подперто железом, вплоть до того что будет долбить указанным (при формировании буфера) duty/последовательностью даже при кончине (или занятости) процессорного ядра. Да еще шину потоком команд не грузит, в отличие от софтэрзацев. А рассуждения о хардварных PWM - это прекрасно, но вот захочется пару десятков каналов "хоть какого-то PWM", для например группы светодиодов - и тогда чего? Хардварных каналов ограниченное количество, и вот для них можно и интереснее и требовательнее применения найти.PWM до кучи придумался. Несколько интереснее ... скажем так, "штукам с разверткой". Когда куча светодиодов на энном порту имеет некий смысл. Вот там таймер ... может очень круто вписаться. Такой себе аппаратный blitter/display controller, если можно так сказать про такую штуку.
Re: Ассемблер для STM32. Сложно ли, стоит ли пытаться?
Пт янв 08, 2021 15:04:41
Но выпадут ли из порта трансферы и прокатят ли уж какие получатся тайминги (дисплею это важно)
Один канал таймера использовать как имитацию ноги WR, вторым каналом пинать дма. И да, дма уже загрузило данные для дальнейшей работы, если хочется - можно грузить целую пачку данных. Потери данных могут возникнуть только в одном случае: другой дма с более высоким приоритетом фигачет в режиме нонстоп.